AEO/GEO: Evolving from Web Pages to the Content Lake
Combine new tactics with a strategic approach to content structure to get ahead in the new AI era. Regardless of whether you call it AEO, GEO or just SEO.

Richard Lawrence
A data scientist and developer, with an interest in marketing and search.
Published
People aren’t just typing into search bars. They’re asking assistants to answer questions, make recommendations, and take action. These systems don’t browse like humans. They scan for facts, structure, and signals they can reason with.
Regardless of whether you call it SEO, AEO, GEO; to get ahead and reach the right audience in this new medium, you need to surface content from across your business for AI assistants to learn from – in whichever format they require. As a Content Operating System, Sanity is the perfect platform for this new search paradigm – allowing you to structure, manage, and deliver all of your business content from its Content Lake.
Overnight disruption; years in the making
ChatGPT launched at the end of 2022 and caused a big bang in terms of public perception towards there being a new way to retrieve and digest information – appearing to be an almost overnight change.
But the progression to this point can be traced back through many smaller advancements over the years.
I wrote a post back at the beginning of 2019 talking about the path for the evolution of search (find it on Wayback machine here) and would say it still broadly holds true today.
Within the post, I referenced the three paradigms for 'assistive systems', taken from a 2018 paper by a Distinguished Scientist at Google, called Andrei Broder. The three paradigms are:
- Conducive: a traditional search engine, the objective of which is to narrow down the options for the user e.g. the traditional ‘ten blue links’
- Subordinate: a system that processes content and makes a recommendation—examples in 2018 included Google Assistant or Alexa
- Decisive: a system that makes the decisions needed to fulfil an objective—examples in 2018 included driverless cars

You can also see how this maps to search engines (conducive), chat assistants (subordinate) and agents (decisive) in the era that has sprung up around us over the last couple of years.
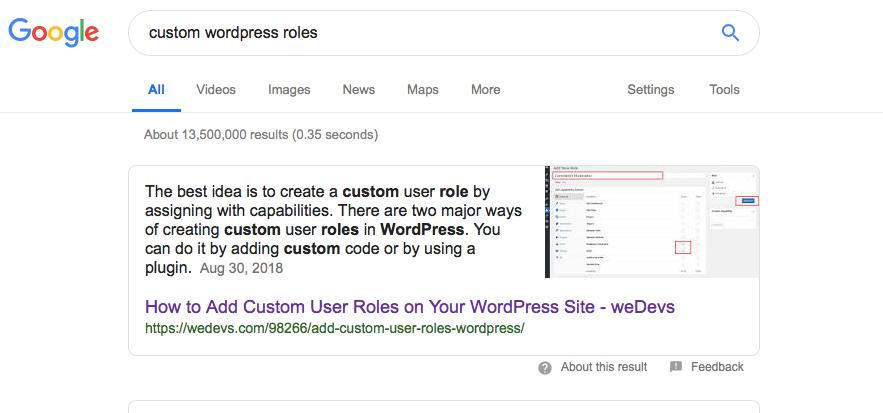
Google's decade of failing to push us beyond search engines
At the time of writing back in 2019, features like featured snippets and knowledge panels had begun to transform the traditional Google search results page into something more along the lines of a subordinate system. But this was very pedestrian, trying not to shake things up too much and taking users on very small baby steps (featured snippets first showed up in 2014!).
Google's long term vision had always been much more ambitious.
It has long stated its ultimate objective was to create a system like the assistant from Star Trek–here's its head of Search discussing this back in 2013.
Attempts to progress in this direction include the moderately successful Google Assistant (surprisingly still the driver for the most viewed Wikipedia entry in 2024, so usage is not trivial - and not forgetting competitors such as Siri and Alexa), but also other ideas that disappeared in transit (anyone remember Google Duplex?).
Unfortunately for Google, it was ChatGPT and other LLM-based assistants that managed to bring a large audience firmly into the paradigm of subordinate systems for the first time and for the long haul (quite incredibly, 90% of users that now sign up to ChatGPT are still using it a month later).

The success of OpenAI and others can at least be partly attributed to not having the responsibility that burdened Google as the supposed guardian of the web, and the conservatism born out of that, which impeded its progress. And probably even more so, because Google's cushy ad revenue discouraged innovation towards a system that didn't give users options that included sponsored placements.
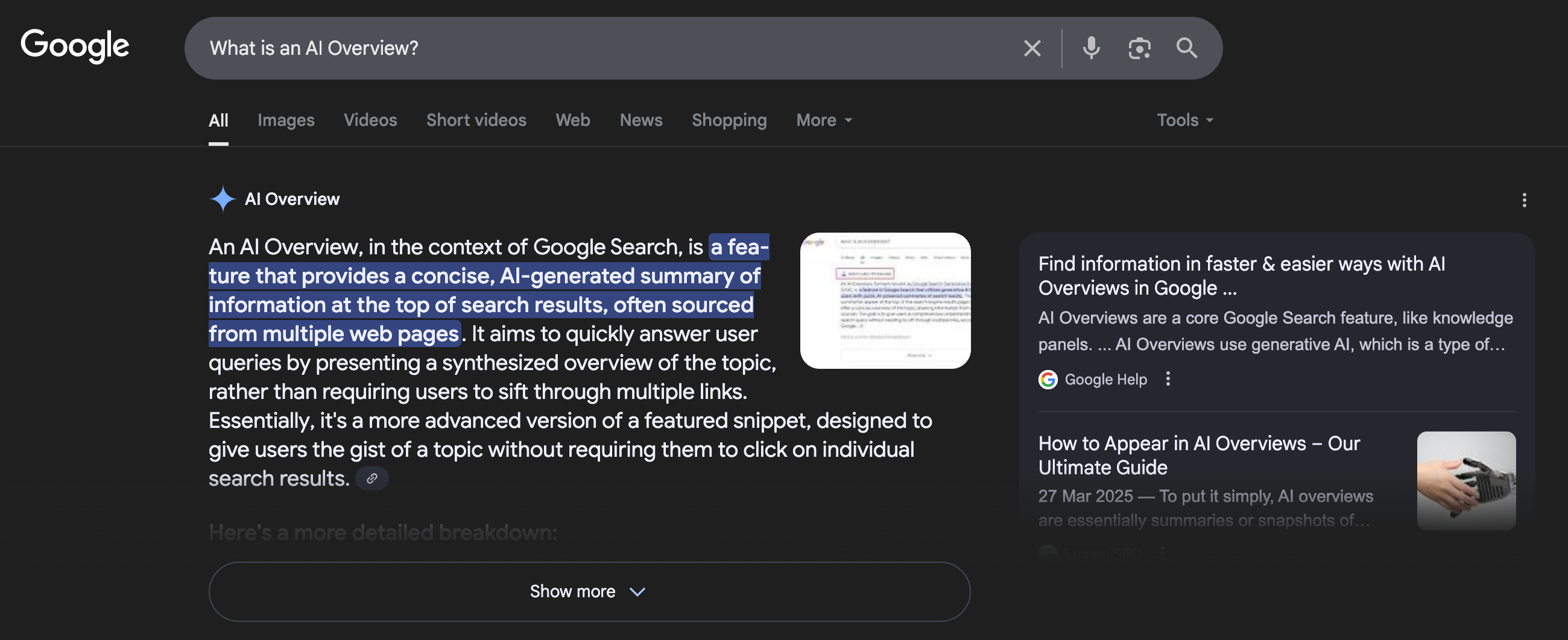
It is now trying to play catch up and further transform its conducive system into a subordinate one, with AI Overviews taking over the mantle from rich answers, and AI Mode blurring the lines even further. The jury is out as to how successful it will be.
After only a few years, chat assistants are yesterday's news
Whilst the subordinate paradigm took decades to embed, we seem to be moving into the decisive paradigm at rapid pace, after only a few years.
AI agents are driving this–they aren't simply systems that provide us with information, but actively make decisions on our behalf whilst working towards an end goal.
AutoGPT was an early example back in April 2023, which allowed you to set goals and then watch as the AI autonomously worked through multiple steps to achieve them - researching, planning, and executing tasks with minimal human intervention.
Since then, we've seen rapid advancement with developer tools such as like Cursor and Windsurf that can execute multi-step tasks with minimal human intervention.
We're in a new world where AI agents can search the web, analyze data, make purchases, and even negotiate on our behalf.
Feeding the machines in the new era of search
The idea I explored in the 2019 blog post still rings true:
The new search engine is now becoming more like a super-user–rational and able to consume a vast amount more information than a real user, before making a recommendation.
Regardless as to whether the assistant is making recommendations or decisions, you need to give it facts and data to work from - for example:
- Product specifications
- Reviews
- Community discussions & solutions
- Social posts
Giving the LLM as much as possible to learn from will be the key for the future in terms of reaching the right customers - to do this, we need to move beyond the concept of 'website content' to 'business content'.
What is all the content that might be useful to learn about you as a business or brand and where is it stored? It needs to be aggregated in one place so you can craft a comprehensive and compelling story for a proxy that deals in data and facts (more about this later).
There are then two ways that these facts are interpreted and communicated to the user via the LLM:
- Conversations: what they already know about you via their training set.
- Research: how they find out specific and up-to-date information about you using tools they have access to, such as search APIs. This can be just a search or a deep research process.
Adding yourself into the conversation
To be referenced in isolated conversations, information about your business needs to be part of the training set for the LLM - the inventory of content (millions of documents) that they initially learned from. This is often out-of-date to some extent. For example, Open AI's o4-mini model has a knowledge cut off of June 2024.
To ensure you are part of the training set for LLMs, you need to:
- Ensure your content is crawlable: the web is used to train LLMs, retrieving HTML and converting to markdown. Rendering with JavaScript is not part of this (at the time of writing). If your web pages need JavaScript to render, that is a problem you need to address. In addition, you need to check your CDN settings to ensure AI crawlers aren't blocked, which Cloudflare recently added as a default setting.
- Earn references on external authority sources: being included in reputable publications, industry reports, academic papers, and other high-quality sources increases the likelihood that information about your brand will be included in LLM training datasets.
- Add 'share to LLM' buttons on your content: you can easily create a button with a URL that will open ChatGPT (or others) with a custom prompt. This is a great way to become featured in the memory of your audience's favourite assistant.
Optimizing for real-time AI queries
Traditional search engines will still have a part to play - ChatGPT uses Bing as its search tool (search engine) to retrieve relevant content for your query or discussion.
In addition, there will be methods to directly communicate with LLMs (jury is out on which format this will entail - more about this later).
For now, you should:
- Ensure your content is crawlable: same as above. When using search tools to research and fetch content, JavaScript is not executed. If your web pages need JavaScript to render content, then it can't be processed. Check your CDN settings to ensure AI crawlers aren't blocked.
- Maintain other traditional SEO practices: since traditional search engines are used by LLMs (as well as users!), traditional SEO practices to gain high rankings for relevant queries - such as meta tags and earning links - still apply.
- Pay attention to Bing: Bing was largely ignored for SEO for many years owing to low market share, but ChatGPT has changed this. Make use of Bing-specific features like the IndexNow API, which ensures Bing can reindex as soon as changes are made.
- Use prompt chain data to understand potential search behavior: you can see the search queries that assistants such as ChatGPT and Gemini use by inspecting requests in developer tools. This can give you insight into what kinds of searches are performed and therefore what kinds of questions to answer.
- Answer potential questions clearly and concisely: When LLMs search for information, they look for direct answers to specific questions, with semantic relevance being important. Structure your content with clear headings, bullet points, and concise explanations that directly address common questions in your industry. Avoid overly elaborate language and focus on providing factual, authoritative information that an LLM can easily extract and present to users.
- Maintain comprehensive a knowledge base for business content: Create detailed FAQs, product documentation, and support resources that can be easily accessed and referenced by LLMs during their research phase. Think wider than just 'web content' in terms of what is accessible.
Why the Content Operating System beats CMSes for AI
Sanity was created on the premise of treating content as data, allowing you to store all of information relating to your business in one place - one place for all your content, so you can aggregate and present it however you want, to whoever you want. Whether that be via a website for users or the preferred format for an LLM (more about this in a minute).

You can store all content within Sanity (within the Content Lake) to present on your website and get indexed via search - or feed directly to LLMs using whatever method they prefer, either now or in future. Just a few examples:
- Use your review collection platform's API to pull your reviews into Sanity so you can tag and segment.
- Store your User Generated Content from your community platform so you can present crowd source solutions at scale.
- Pull in your best performing adverts and social content to use for inspiration for ledes and meta data, or feed directly to LLMs to learn about your business.
There are also additional features of Sanity that give you an advantage in the world of subordinate assistants such as Content Releases that will help you deliver changes to your business content at scale when needed, and the Live CDN which ensures your content is up-to-date in realtime for when LLMs visit your content via search tools.
Future-proof your content for any AI format
On the preferred format for the LLM, an early example has emerged with llms.txt and llms-full.txt.
One reason why people dislike this format is they see it as a separate inventory of content to manage or maintain. With Sanity, this is not the case - you can easily generate a llms.txt file directly from your existing content, without duplicating effort. As part of the Content Operating System, the Content Lake allows you to define structured content once and output it in multiple formats - whether that's for your website, mobile app, or now via a text file.
// Example: Query plain text for a llms.txt from Content Lake
const llmContent = await client.fetch(`
*[_type in ["product", "post", "faq"]] {
title,
"content": pt::text(body),
"metadata": {
category,
lastUpdated,
relevance
}
}
`)However, I can also foresee further formats coming to the fore in the future, such as dedicated API endpoints that allow for real-time content retrieval, structured JSON formats that better represent complex relationships between content entities, or even specialized knowledge graphs that LLMs can directly query.
Whatever the format, the key is that with a Content Operating System like Sanity, you are in a fantastic position to present all of your business content to an LLM however they will request it—be it through a text file now or via a dedicated API endpoint in the future. Having stored all of your business content in one place, you can provide everything for them to learn from—reviews, community content, product specs. Not simply content created for your website.
Your AI-ready SEO plan
To recap: search has evolved from showing options to making decisions. While Google spent decades perfecting ten blue links, AI agents are already negotiating deals and writing code. You're no longer just optimizing for human clicks—you're feeding data to machines that determine whether customers ever see your brand.
Here's what you need to do:
Audit your JavaScript-rendered content
AI assistants can't execute JavaScript when crawling. If your content requires client-side rendering, it's invisible to LLMs. Run a crawler on your site and fix what doesn't appear.
Check your CDN settings
Check your CDN settings to ensure AI crawlers aren't blocked, which Cloudflare recently added as a default setting.
Consolidate your content sources
Product specs in one system, docs in another, reviews somewhere else? AI agents need unified access to everything. Map all your content repositories and plan your consolidation strategy.
Build structured content across all content types
Every piece of content needs clear structure that machines can parse—from product details to support docs to community discussions.
Create real-time content APIs
Static sitemaps won't cut it. AI agents will expect fresh data on demand. Build APIs that serve your complete content catalog with sub-second response times.
Add LLM sharing buttons
You can easily create a button with a URL that will open ChatGPT (or others) with a custom prompt. This is a great way to become featured in the memory of your audience's favourite assistant.
Implement llms.txt (but prepare for what's next)
Start with the current standard but architect for flexibility. Today it's text files, tomorrow it could be specialized endpoints or knowledge graphs. With Sanity, you are prepared for any format - for example, you can easily generate a llms.txt file directly from your existing content today.
Set up content synchronization workflows
Your content changes constantly. Build automated pipelines that keep all formats—web, API, llms.txt—synchronized without manual intervention.
With Sanity's Content Lake, you're not starting from scratch. Your content already lives as structured data, ready to flow wherever AI needs it—whether that's through GROQ queries, auto-generated text formats, or whatever comes next. The infrastructure is there.
Time to put it to work.
Find out more about Sanity
To find out more about how a Content Operating System can prepare you for the future of search, watch the full demo or simply start building today.