We don't write code anymore
An engineering manager’s field report from an AI-first engineering team

Vincent Quigley
Software Engineer Manager
Published
Something has shifted in software engineering. Not in the abstract, future-of-work sense. In the daily mechanics of how code gets planned, produced, reviewed, shipped, and monitored.
I think we are now in the fourth generation of coding.
The deliberately uncomfortable version is that we no longer write code.
This is a field report on how my team works now.
I'm Vincent, an engineering manager at Sanity who still codes, and I have been using AI in engineering work for about 2.5 years. Nine months ago, I moved into AI-first workflows and wrote about that journey in "First attempt will be 95% garbage" when everything felt new and uncharted. This post is about what changed after AI-first workflows became the default.
Over the last few months, my team has become AI-first; we build, release, and monitor software with AI as the main working surface. I mean "we no longer write code" literally enough to be useful, but not so literal as to be silly. Code still gets produced. Pull requests still get reviewed. Systems still ship. What has changed is the job's center.
A few weeks ago, I asked the team how much code they still write by hand. This is a team of senior engineers, each with at least 10 years of experience. One person said 1%. Another said they had tried writing code directly, then found themselves going back to the agent because it no longer felt like the intuitive path. That can sound scary. I do not think it needs to be.
That changes what engineers need to be good at, how teams should organize around the work, and what engineering managers need to pay attention to. This post is about those changes. The new development pipeline, the uncomfortable failure modes, and why judgment matters more when implementation gets cheaper.
The four generations of coding
The frame I use is that software engineering has moved through four generations of abstraction. Each generation changed what engineers wrote, how they learned, and where the hardest problems in the job lay.

The first generation was assembly. Engineers wrote instructions close to the machine. The work was coding registers, jumps, memory addresses, and manuals open beside them. It involved direct control and precise knowledge of the hardware.
MOV AL, 61h MOV BL, 62h ADD AL, BL
The second generation was high-level languages. Engineers moved from machine instructions into languages like C and BASIC, and later C++, Java, Python, PHP, and JavaScript. The compiler or interpreter became a major part of the feedback loop. It told you when you had broken the language’s rules, and it gave you a higher-level way to describe what the machine should do.
#include <stdio.h>
int main() {
printf("Hello, World!");
return 0;
}The third generation was frameworks and cloud. Engineers wrote compositions of libraries, APIs, managed services, and infrastructure. You did not need to know how Stripe, AWS queues, or every database worked internally to build with them. You needed to understand the interfaces, trade-offs, and failure modes. This was the Stack Overflow and Google era: the community became part of the work.
const response = await fetch('https://api.example.com/data');
const data = await response.json();
console.log(data);The fourth generation is AI-first development. The unit of work is changing again. We are now dealing with intent, context, and conversation with models. I do not ask Google much anymore. I ask an agent. The agent has access to the codebase, documentation, logs, connected tools, and enough surrounding context to give me better answers faster. I learn by interrogating it, pushing on trade-offs, and asking it to explain the shape of a problem back to me.
"Create a function that fetches user data from the API endpoint, handles loading states, and logs any errors to our observability tool."
Every generation of abstraction looks suspicious at first. Something is always lost. But again and again, the gain has been worth it because the cost of building drops.
Now, with AI-first development, the cost of implementation has collapsed so far that some of the rituals we built to protect expensive code no longer make sense.
Code was the cost. The product was always the point.
For decades, writing code was one of the most expensive parts of software engineering. We built our habits around that cost. We wrote requirements documents because implementation was expensive. We spent weeks on designs because changing direction late was expensive. We estimated, planned, staged, and reviewed partly because we could not afford to build the wrong thing.
Those activities still matter. In some cases, they matter more. But the reason for them has changed.
AI has made producing code dramatically cheaper, especially in terms of time. The question is no longer, "How do we write code faster?" It is, "What does software engineering look like when code is cheap?"
From where I sit, engineering moves up a level. The work worth protecting is deciding what should exist, describing it clearly, breaking it into the right pieces, steering implementation, reviewing the result, and understanding whether it actually worked. The code still matters. It is just no longer where the hardest constraint sits.
Writing code was never the point. Creating useful products and services for customers was the point. Code was the cost of getting there.
The development pipeline has changed
When implementation stops being the bottleneck, the development pipeline reorganizes around context, autonomy, and review.
I treat most work as a set of long-running pipelines. Not everyone on the team works exactly this way, but the pattern is becoming familiar: the agent is not just there for drafting of the code. It stays involved as a partner throughout the change lifecycle from context to spec, build, review, release, and monitoring.
- Shape the context.
- Produce a spec.
- Let an agent build and iterate until it is ready for human review.
- Review the diff.
- Push back.
- Tighten tests.
- Ship.
- Monitor.
- Iterate.
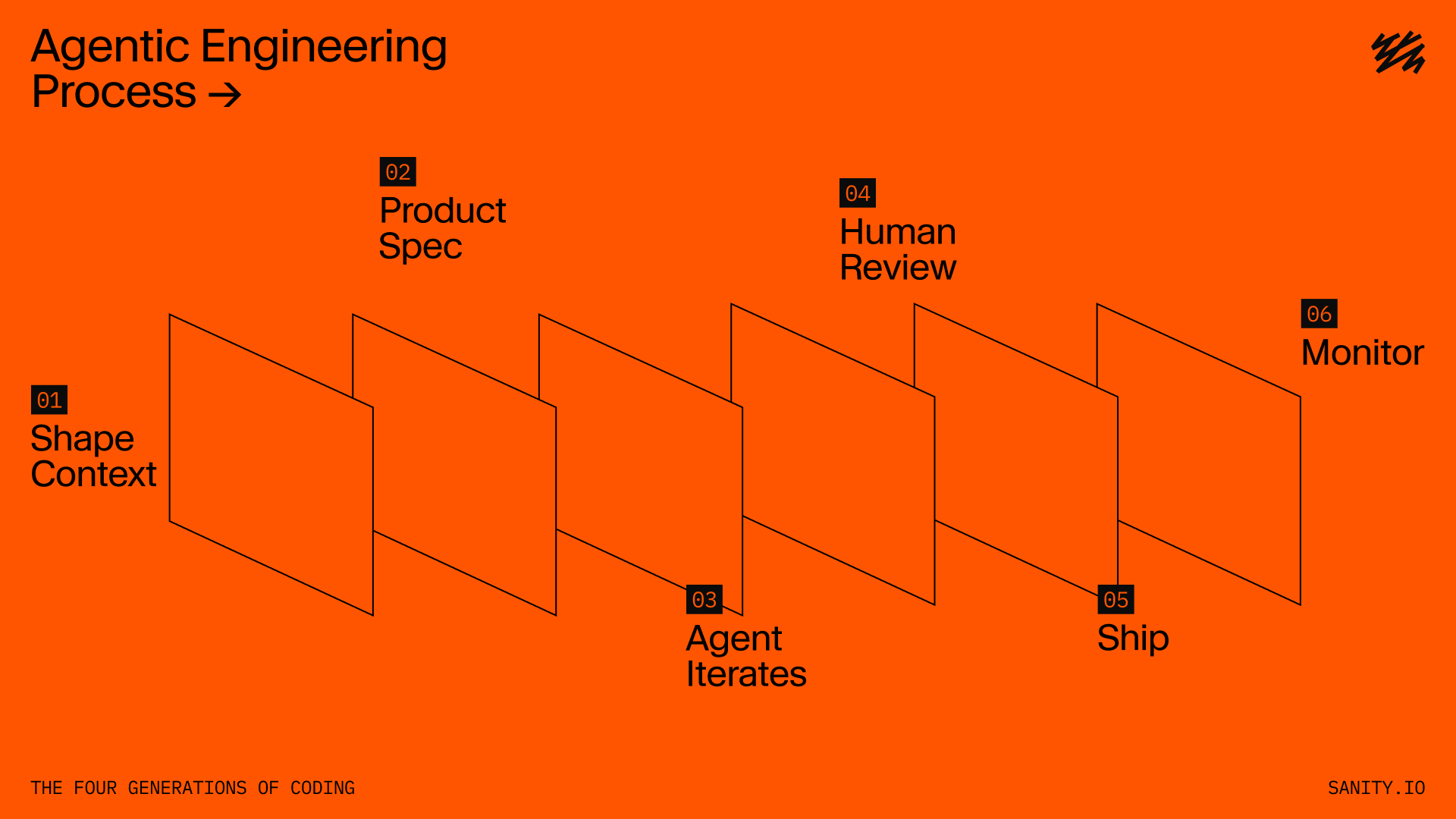
This doesn’t mean we don’t “own” the code anymore. Just that the agent changes where ownership shows up.
Before an agent writes code, I need to tell it what matters: the goal, constraints, existing patterns, edge cases, success criteria, and the boundaries of the change. The first output is often not code. It is a plan or spec that I can review, challenge, and share with others. For the agent to be successful and not waste everyones time, I have to own that those things are good, clear, maps to our business goals, and are well thought out.
You’ll need to hone your reviews
Then the building starts. I try to make the agent as autonomous as possible before the work reaches a human. It should not stop after one pass and wait for me to spot every obvious issue. If a linter fails, it should fix it. If tests fail, it should understand the failure and iterate. If an automated review catches something obvious, it should resolve it before a human spends attention on it.
But the human review becomes sharper, not softer.
I still own the artifact. Before a pull request goes to someone else, I need to know what changed and why. I need to inspect the boundaries, tests, product behavior, and failure modes. I need to be able to stand behind the work.
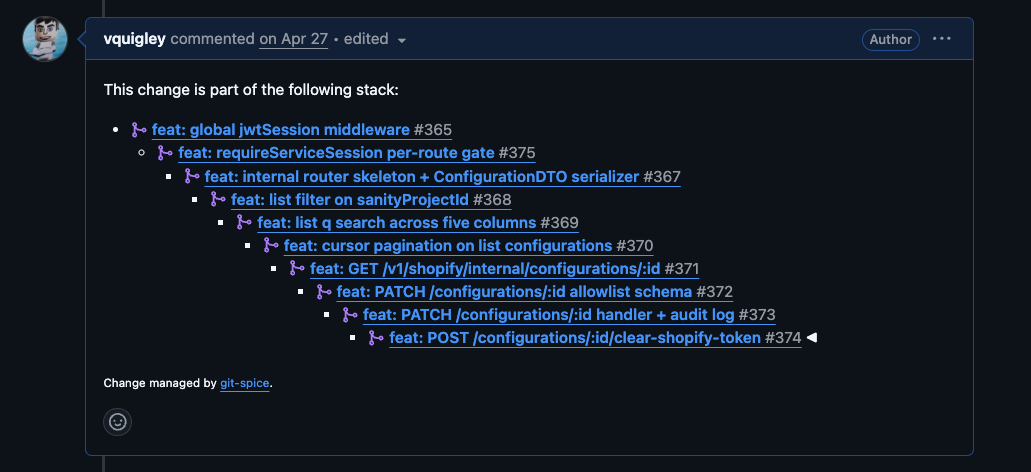
One rule matters more than almost anything else: keep reviews small. I train agents to produce small pull requests, ideally around 500 lines. If it becomes 1,000 lines, fine. If it becomes 10,000, the process has failed. No one is reviewing that properly. Stacked, focused pull requests are much easier to reason about than one giant blob of generated code.
A recent PR stack shows what this looks like in practice. Claude created the stack for me. I did not write the code, and I did not tell the agent how to break down the work. By the time I reviewed it, the agent had created the PRs, verified CI, and responded to independent AI reviews built into the PR CI pipeline.
The merge is not where it ends
Another thing to get used to is that the pipeline does not stop at merge.
After release, the same context can help monitor bugs, adoption, and behavior in production. A useful agent is not only a code generator. It can become a long-running assistant that knows what was built, why it was built, and what signals matter after it ships.
This part is easy to miss. A lot of people still treat the PR as the point where the agent’s job ends. I think there is a lot of value in keeping the agent running after merge: agents that keep the release context, watch the signals, and help decide what needs attention next. You invest a lot of time in giving an agent context, make sure to squeeze all the value out of it that you can.
The uncomfortable parts
This way of working has increased my output. It has also made the process's weak points much harder to ignore.
It costs enough money to make your head turn
My AI spend is around $2,000 a month. That is a lot of money but for me, the productivity gain is worth it. The output is higher, the quality is better when the process is disciplined, and I learn faster. But it is not free. For most organizations rolling this out broadly, cost is a real operating question, not just a rounding error.
Teams need to treat AI usage like infrastructure. This means measuring it, budget for it, and ask whether it is producing better outcomes, not just more output. But the cost conversation has to include opportunity cost too. If AI helps you ship the right work sooner, the question is not only what the tools cost. It is what you would have spent in time, delay, and missed learning without them.
AI accelerates what is already there
AI does not create good products or engineering judgment. It accelerates whatever habits are already there. That is great when someone has strong product instincts, technical taste, and enough discipline to verify the work. It is dangerous when someone is used to being handed narrow tickets, producing exactly what was asked for, and moving on without thinking about the outcome. An agent can make a good engineer faster. It can also make weak habits louder.
The concern here is not just bad output, it is output that is technically good but product-wrong.
When implementation feels cheap, it becomes tempting to keep going. Cover one more edge case. Add one more abstraction. Solve one more imagined scalability problem. The result can look impressive, but you still end up with code and documents that humans need to review, test, understand, and maintain. KISS principles still apply.
When the cost of implementation drops, the cost of poor judgment becomes more visible. As an engineering manager, I do not think the answer is to add more ceremony or slow everyone down. The expectation is that engineers can work more independently, at higher quality, and with greater output. That is why we are investing in this technology and early adopters are already showing what is possible.
The answer is to move more attention to the places where judgment shows up: the spec, the size of the change, the review bar, the quality of the written argument, and the signals after release. Be honest with the engineer when the work doesn’t meet that expectation. It will take months for some good engineers to get up to the expected standard so give them time and coaching.
Slop is unacceptable
AI can generate volume. In a very short time span (despite it’s “this will take weeks of work” estimates) it can spew out docs, comments, tests, specs, Slack messages, and pull request descriptions. Some of it is useful. Some of it is polished nonsense. That creates a new kind of quality problem. People send work they have not really read. They share arguments they cannot defend. They approve text that sounds coherent but says nothing precise.
We cannot allow that to become the new normal.
Intent === ownership
If your name is on the work, it is your work. Saying “AI helped with this” does not lower the bar. It is not a disclaimer that transfers validation to the next person. If anything, it means you should have reviewed it more carefully before sending it, because you did not create every part of it yourself. The agent helped, but you are accountable for the result. It was you who set it lose. So you need to be able to explain it, defend it, revise it, and decide whether it should exist at all.
There are times when it is fine to share rough AI-assisted work. If you are looking for a temperature check on direction, say that clearly: “This is still rough, but I want to make sure we are aligned on the structure before I spend more time refining it.” Then the expectation is different. I will not review every line or take action from the output. I will help steer the next pass.
The standard I keep coming back to is the answer to the question “can this produce a useful conversation?” A spec, review comment, Slack message, or decision memo should be concise, actionable, and clear enough that others can respond meaningfully. If it cannot do that, it is not ready to send.
Review is now a larger part of the job
A lot of my day is spent in reviews. I review the specs an agent produced for me. I review the docs that other people produced with agents. I review pull requests from humans, pull requests from agents, and pull requests from humans using agents. I review my own agent's output before anyone else sees it.
When you wrote code by hand, you usually thought about every line as you typed it. With agents, that is no longer true. You may understand the goal and the architecture, but the implementation can contain decisions you did not personally make.
The ideal did not change. You were always supposed to review carefully. What changed is the cost of not doing it. When you wrote the code yourself, most understanding came from the act of writing. With agents, that understanding is no longer automatic. If you do not review carefully, you may be approving work you have never properly internalized. Not performatively and not just "looks good." You need to read the code, inspect the tests, verify the behavior, and ensure the work aligns with the intent.
Testing matters more, not less. Linters matter. CI matters. Automated review matters. Red-green testing helps because it forces the agent to prove that tests fail for the right reason before making them pass.
The review bar cannot drop just because the code was cheap to produce.
The work can be exhausting
AI did not remove the hard part of engineering. It removed some of the breaks. Typing code was never the hardest part, it was thinking. But writing code did two useful things: it gave us a rhythm, and it forced us to internalize the system as we went. You saw the dependencies, edge cases, and small decisions line by line. With agents, you must meet all of that later, in one review pass.
That makes the work cognitively heavier. You are not just checking output. You are rebuilding the mental model that used to accumulate during implementation.
Agentic work also makes it tempting to pretend you can multitask. You cannot. You are still one person with one thread of attention. What changes is that more of the work can become asynchronous. You can start an agent on one task, move your attention elsewhere while it runs, then come back when it needs a decision.
In that sense, the work starts to feel a bit like CPU scheduling. The processor is not doing everything at once. It is allocating cycles, waiting on IO, resuming work, and deciding what gets attention next. The engineering version is deciding which agent gets context, which task is blocked, which output is ready for review, and which thread should be killed before it wastes more time.
That can increase throughput, but it does not make attention free. The tools make parallel work easier to start. They do not make human judgment any less finite.
Fair warning, though: it can become addictive. When an agent is making progress, the next prompt is always right there. One more fix. One more review pass. Move one more agent on so its output is ready for you in the morning. One more attempt to get it over the line. Phew! There is a serious dopamine hit from seeing documents and features assemble in front of you, and it can be difficult to step away. It feels good to be so productive. But it has a cost that we are not accounting for yet.
Some days, I leave the desk feeling like I did 2.5 days' worth of work in one day. That can sound like a productivity win. It can also become a sustainability problem. We do not yet have good practices for this. We need them.
What this changes for teams
The work did not disappear. It moved up a level. For engineers, the valuable skills are judgment, taste, verification, product thinking, and systems thinking. Syntax still matters, but it is not enough. Knowing what good looks like matters more.
For teams, ownership becomes broader. Engineers can do more product and UX work. Product managers can get closer to implementation. Designers can work on production code. The roles start to bleed into each other, even if people still have specialties where they are strongest.
Managing people managing agents
Engineering management changes too. We are managing people whose job is to direct agents. Those engineers are expected to operate at a level many were never explicitly trained for or even asked to think about for the first decade of their career. The job is no longer to turn a ticket into code. It is to frame the problem, constrain the work, steer implementation, review the output, and decide whether what shipped actually moved the product in the right direction. That’s a different craft.
The coaching changes as well. I spend more time pushing engineers away from thinking in code first and toward thinking in systems, behaviors, and products. In a way, that is what we always wanted. Good engineers were never supposed to be measured by syntax alone. But when so much of the work was spent discussing, writing, and reviewing code, it was easy to let the bigger questions become implied or secondary. AI-first development makes that harder to hide. If the code is cheap, the quality of the thinking becomes much more visible.
Smaller teams can do more
That changes the team shape. You need fewer people in the room to move a piece of work from problem to product decision to implementation to release. A smaller pod with strong context can carry more of the path itself, which means fewer handoffs and less coordination drag.
Clarity becomes the constraint for what you can deliver. If the product thinking is vague, AI will not save it. It will expose the ambiguity faster. You can get the wrong thing back in days instead of months, which is useful only if you are willing to notice, learn, and correct course.
The teams that benefit most will not be the ones that generate the most code. They will be the ones who make better decisions faster.
What this changed for me
There is a personal reason this shift matters to me. For years, I felt a real split between management and individual contributor work. Management meant people, planning, shaping, stakeholder conversations, and delivery. IC work meant staying close to the code and the product. I loved both, but I could not do both well at the same time. I always felt like I had to choose.
AI changed that.
Because the cost of implementation dropped, I can be an engineering manager and still ship meaningful production work alongside my team; not as a late-night side project, not as a nostalgic attempt to keep coding but as part of how I operate. Some of that is because the management shape is familiar: set direction, create context, inspect the work, give feedback, and decide what happens next. The difference is that some of those loops now involve agents as well as people.
This is why the change in the industry feels so different for me from a normal tool upgrade. It did not just make me faster. It changed the kind of engineering career I could have.
You should be in the room
This is the biggest shift I have seen in software engineering since the Internet. Maybe that sounds too large. Maybe it is. But the adoption rate, the capability curve, and the change in day-to-day work are all moving fast enough that I do not think we can treat this as a side topic.
We are going to waste some time. We are going to waste some money. We are going to be wrong about a lot of things. That is the price of working while the industry is still changing shape.
You should be in the room while this gets figured out, not watching from the sidelines while everyone else works it out.
(and if you got this far, you might be interested in our careers page)