An AI shopping assistant that actually checks inventory
- Give an AI shopping assistant structured access to your product catalog, inventory, and pricing so it answers with real data instead of hallucinated specs
- Keep business rules like margin floors and regional restrictions in Sanity documents the merchandising team can update without a deploy
- A starter you can adapt: product Q&A, stock checks, and recommendation logic ready to extend

Knut Melvær
Principal Developer Marketing Manager

Ken Jones
Community Experience Engineer at Sanity

John Siciliano
Senior Technical Product Marketing Manager
Published:

View transcriptClose transcript
Your customer asks "show me blue wool sweaters under $100 in size M." Your chatbot searches for semantically similar products and returns a $400 cashmere coat, a cotton t-shirt that happens to be blue, and a wool scarf. All related. None matching.
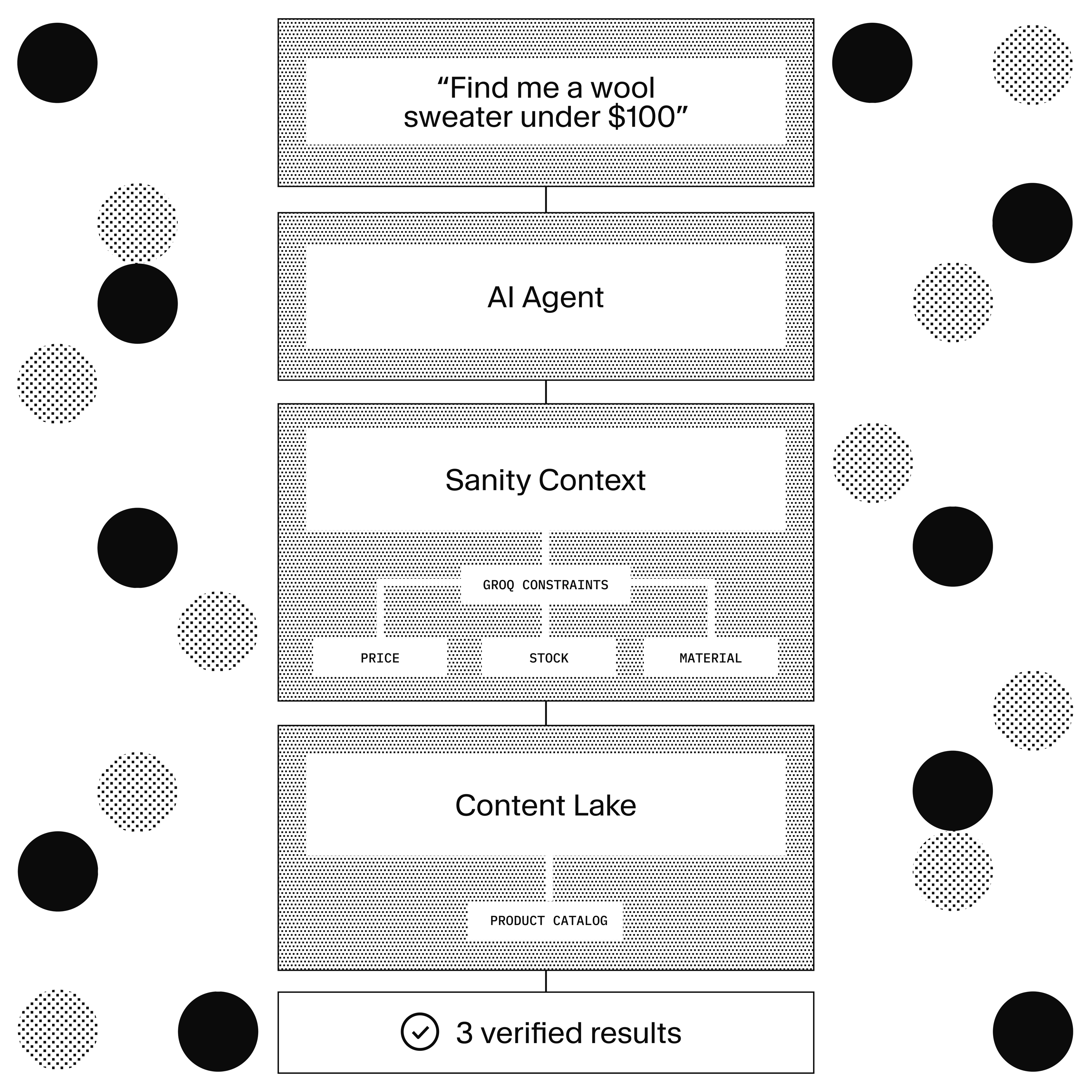
The agent in this guide doesn't search for similar products. It writes a GROQ query: category is sweaters, color is blue, materials include wool, price under 100, size M available in stock. Every result matches every constraint. That's the difference between a search engine and a shopping assistant.
This is what AI Content Operations looks like in e-commerce: your content schema becomes the agent's constraint system, and your editorial workflow becomes the agent's improvement loop.
For technical leaders evaluating this approach: the agent enforces business rules (price floors, regional restrictions, inventory status) without a separate rules engine. The merchandising team updates constraints by editing Sanity documents. No ML team required. No retraining cycle. The agent improves because the content improves.
Quickstart
This guide goes in depth on how to build agents that are less likely to hallucinate for your customers. But you can also clone the example to get a quick feel for how it works:
pnpm create sanity@latest --template sanity-labs/starters/ai-shopping-assistant --package-manager pnpm pnpm bootstrap
View The repository for all the details.
Install the skill:
npx skills add https://github.com/sanity-io/context
Try this prompt:
"Show me blue wool sweaters under $100 in size M"
Read the docs: Sanity Context documentation
What you'll need
- Sanity Context + MCP: One endpoint gives any AI agent structured access to your product catalog. The agent receives a compressed schema (~50-100 tokens per type instead of 500-1000 raw) and generates GROQ queries directly. No vector database to maintain.
- GROQ: The agent's query language. Predicate logic that enforces real business constraints: price ranges, category filters, variant availability, nested references. The agent writes queries, not keyword searches.
- Sanity Functions: Serverless compute that reacts to content changes. In this example: surfaces content gaps, feeds the self-improving loop, and reacts to catalog updates.
What's covered
Connect your product catalog to an AI agent via MCP and watch it generate GROQ queries with real constraints. The agent validates filter values against your actual catalog before applying them. You'll store the system prompt in Sanity so your team can edit it without a deploy. Conversations get logged and classified automatically, surfacing content gaps so the agent improves over time.
Why similarity search fails for product catalogs
Similarity search treats every part of a request as a signal to match against, not a constraint to enforce. "Blue" is a hint, not a filter. "$100" is context, not a ceiling. "Size M" is a preference, not a requirement. That's the core problem.
What similarity search returns:
1. Cashmere Blend Coat ($389) — wool-adjacent, wrong price 2. Blue Cotton Tee ($29) — blue, wrong material 3. Merino Wool Scarf ($65) — wool, not a sweater 4. Navy Cardigan ($110) — close, over budget
Semantically similar. Practically useless. The customer wanted sweaters. They got a coat, a tee, a scarf, and a cardigan that's over budget.
What the agent in this guide generates:
*[_type == "product"
&& "sweaters" in categories[]->slug.current
&& "blue" in variants[].color->slug.current
&& "Wool" in materials[]->title
&& price.amount < 100
&& count(variants[available == true && "M" in sizes[]->code]) > 0
] {
title,
price,
"colors": variants[].color->title,
"sizes": variants[].sizes[]->code
}Every result is a sweater. Every result is blue. Every result contains wool. Every result is under $100. Every result has size M available. The agent didn't approximate. It queried.
Connect your product catalog with Sanity Context
Six lines to connect an AI agent to your product catalog:
import {createMCPClient} from '@ai-sdk/mcp'
let mcpClient
try {
mcpClient = createMCPClient({
transport: {
type: 'http',
url: process.env.SANITY_CONTEXT_MCP_URL,
headers: {
Authorization: `Bearer ${process.env.SANITY_API_READ_TOKEN}`,
},
},
})
} catch (error) {
console.error('Failed to connect to Sanity Context:', error.message)
throw error
}That's the connection. The agent gets several tools, the most important ones are:
initial_context — Compressed schema overview. The agent sees your product types, fields, and relationships in ~50-100 tokens per type.
groq_query — Execute GROQ queries against your catalog. The agent writes queries with real constraints.
schema_explorer — Detailed schema for specific types. When the agent needs to understand a field's structure, it asks.
array_field_reader — Read and navigate array fields within a document. Useful for inspecting Portable Text, structured arrays, and nested content without loading the full document.
The agent sees your product schema (product, brand, color, size, category, material, productVariant, price) and generates GROQ queries that respect the structure. It knows price.amount is a number, color is a reference to a color document with a slug, variants is an array of objects with size references. Schema awareness is what makes the queries correct.
The example initializes the MCP client and system prompt in parallel. No wasted time:
let mcpClient, agentConfig
try {
;[mcpClient, agentConfig] = await Promise.all([
createMCPClient({
transport: {
type: 'http',
url: process.env.SANITY_CONTEXT_MCP_URL,
headers: {
Authorization: `Bearer ${process.env.SANITY_API_READ_TOKEN}`,
},
},
}),
client.fetch(
`*[_type == "agent.config" && slug.current == $slug][0]{systemPrompt}`,
{slug: process.env.AGENT_CONFIG_SLUG || 'default'}
),
])
} catch (error) {
console.error('Failed to initialize agent:', error.message)
throw error
}Store your system prompt in Sanity
The system prompt is a Sanity document. Not hardcoded. Not in an env var. In your CMS.
// Schema: agent.config
{
name: 'agent.config',
type: 'document',
fields: [
{name: 'name', type: 'string'}, // "Shopping Assistant"
{name: 'slug', type: 'slug'}, // "default"
{name: 'systemPrompt', type: 'markdown'}, // Full prompt, editable in Studio
],
}The buildSystemPrompt function interpolates runtime variables so the agent knows what page the customer is on:
const systemPrompt = buildSystemPrompt(agentConfig.systemPrompt, {
documentTitle: userContext.documentTitle, // "Blue Wool Sweaters"
documentLocation: userContext.documentLocation, // "/products/sweaters"
})Your marketing team can tune the agent's personality, scope, and behavior by editing a document in Studio. Change the tone from "helpful assistant" to "product expert." Add seasonal context ("It's winter, prioritize warm materials"). A/B test different prompts by creating multiple config documents with different slugs. No code deploy. No PR review. Edit, save, the next conversation uses the new prompt.
Validate filter values against your catalog
This is the most important pattern in the example. The agent doesn't just suggest filters. It validates them against real catalog data first.
The set_product_filters tool has a description that tells the agent exactly what to do:
description: `Update the product listing page filters. Only use AFTER you've used groq_query to: 1) get valid filter values (slugs/codes), and 2) confirm matching products exist. Use the exact values from your query. Do not use this tool blindly.`
"Do not use this tool blindly." That's the anti-hallucination pattern in one sentence. The tool description forces a two-step workflow: query first, act second.
The Zod schema enforces structure and documents the expected values:
import {z} from 'zod'
export const productFiltersSchema = z.object({
category: z.array(z.string()).optional()
.describe('Use slug.current from category documents'),
color: z.array(z.string()).optional()
.describe('Use slug.current from color documents'),
size: z.array(z.string()).optional()
.describe('Use code from size documents, e.g. "L" not "Large"'),
brand: z.array(z.string()).optional()
.describe('Use slug.current from brand documents'),
minPrice: z.number().optional(),
maxPrice: z.number().optional(),
sort: z.enum(['price-asc', 'price-desc', 'newest', 'title-asc']).optional(),
})The .describe() calls. They tell the agent to use slug.current from category documents, not whatever string sounds right. To use code from size documents ("L" not "Large"). These descriptions are part of the tool schema the model sees.
The pattern in practice: Customer asks for blue wool sweaters under $100. The agent:
- Runs
groq_queryto find valid color slugs, category slugs, and size codes - Confirms products exist matching those constraints
- Calls
set_product_filterswith the exact slugs and codes from the query results - The page updates to show matching products
No hallucinated "blue" when the catalog uses "navy-blue" as a slug. No "Medium" when the size code is "M". The agent checked first.
This is the difference between a chatbot that says "try filtering by blue" and an assistant that actually filters the page to show matching products.
The agent sees what you see: client-side page context
The shopping assistant doesn't just query the database. It can see the page the customer is on.
Three client-side tools execute in the browser:
get_page_context captures the current page as markdown. URL, headings, product listings, links. Uses Turndown to convert HTML, strips scripts and styles, truncates to 4,000 characters. The chat widget excludes itself via an agent-chat-hidden attribute so the agent sees the page, not its own UI.
get_page_screenshot takes a visual screenshot of the viewport. Uses html2canvas-pro, resizes to fit within Anthropic's 4,000px limit, sends as JPEG. The agent can "see" the layout, product images, and UI state.
set_product_filters updates the product listing filters on the page. Validates input against the Zod schema, then updates URL search params. The page re-renders with filtered results.
Together, these tools mean the agent can reference what the customer is looking at. "I see you're browsing the sweaters page. Based on what's shown, here are some options in your size that are currently on sale..." Context-aware, not just data-aware.
Rich product references in chat
The customer sees the real product at the real price with a link to buy. Not a text description that might be out of date by the time they click. The agent outputs markdown directives that render as live product cards:
::document{id="product-123" type="product"}A custom remark plugin parses these directives, fetches the product from Sanity, and renders a card with image, title, price, and link. The data is live. If the price changes in Sanity, the card reflects it next time it's rendered.
The plugin is streaming-safe: it filters incomplete directives during streaming (like ::product{ without a closing }) to prevent rendering errors mid-response.
The agent's responses contain actual product data, not stale text descriptions.
Stream AI responses with Vercel AI SDK
The API route uses Vercel AI SDK's streamText to stream responses, with a 20-step safety limit on agentic loops. Client-side, the useChat hook handles streaming and dispatches client tool calls (page context, screenshots, filter updates). A typical product query takes 2-3 steps: one groq_query to find products, one set_product_filters to update the page. See the Vercel AI SDK docs for the streaming implementation details.
Improve the agent through content operations, not retraining
Conversations don't just get logged. They get classified.
Every time the agent finishes a conversation, the response is saved as an agent.conversation document in Sanity. Insights automatically classifies each conversation. It analyzes the messages and populates the following fields:
- summary — factual summary of what the customer asked
- successRate (0-100) — did the conversation achieve its goal?
- agentConfusion (0-100) — how much did the agent struggle?
- userConfusion (0-100) — how unclear was the customer?
- contentGap — content the agent couldn't find (only populated when the catalog is actually missing information)
The contentGap field is the key. When the agent can't answer "what's the return policy for sale items?" because no return policy exists in the catalog, the Function records: "return policy for discounted products." When the agent struggles with "is this sweater machine washable?" because no care instructions exist on the product, it records: "care instructions for product X."
These gaps surface in the Agent Insights dashboard in Studio. An editor sees the gap, adds the missing content, and the next customer who asks that question gets an answer. The agent didn't get retrained. The content got better.
No ML pipeline. No fine-tuning. No retraining. The agent improves because the content improves. Content operations, not data science.
This pattern is already running in production. Content Agent uses the same schema compression approach described here. The e-commerce example extends it with catalog-specific tools and the self-improving content gap loop.
The Agent Insights dashboard
The example includes a custom Studio tool with two views:
Overview: Aggregated metrics powered by GROQ queries against conversation documents. Total conversations, average success rate, average agent confusion, average user confusion, content gap rate (percentage of conversations where the catalog was missing information).
Conversations: A table with date, initial question, AI-generated summary, and content gap. Color-coded badges: green for success rates above 80%, yellow above 50%, red below. Click any row to inspect the full conversation transcript.
All of this data comes from GROQ queries against agent.conversation documents. No external analytics service. No separate dashboard tool. The observability lives where the content lives.
How Sanity Context connects catalog data to AI agents
Here's how the pieces connect.
Customer asks a question in ChatButton (layout-level, every page)
→ POST /api/chat
→ Promise.all: MCP client + agent.config fetch (parallel)
→ buildSystemPrompt (interpolate {{documentTitle}}, {{documentLocation}})
→ streamText (Anthropic Claude, MCP tools + client tools, max 20 steps)
→ Agent calls groq_query (catalog data with real constraints)
→ Agent calls get_page_context / get_page_screenshot (page awareness)
→ Agent calls set_product_filters (validated against catalog)
→ Agent outputs ::document{} directives (live product cards)
→ onFinish: saveConversation (agent.conversation document)
→ Sanity Insights: classifies conversation automatically
→ populates classification + contentGap on conversation document
→ Customer sees streaming response + page updates + product cardsOne source of truth. Product data, system prompt, conversation logs, and content gap analysis all live in Content Lake. When an editor updates a product price, the agent's next answer reflects the change. When an editor adds care instructions, the agent can answer care questions. No sync lag between your CMS and your agent's knowledge.
Schema compression. The agent sees ~50-100 tokens per type, not 500-1000 raw. This compression approach has been in production for 4 months inside Content Agent. It gives the model enough structure to write correct GROQ queries without flooding the context window.
The loop closes. Conversations surface gaps → editors fill gaps → agent answers better → conversations surface fewer gaps. The system improves through content operations, not model operations.
What works and what doesn't
Works well: Product catalogs with structured attributes. Price, size, color, category, material, availability. Any domain where customer requests map to concrete, filterable properties. The agent enforces constraints because the schema defines them. If your data is well-structured, the queries are correct.
Works with caveats: Subjective recommendations ("what would look good on me for a summer wedding"). The agent can filter by occasion and season if those attributes exist in your schema. But style advice requires taste, not data. A well-crafted system prompt can acknowledge the subjective element and frame suggestions as starting points, not definitive answers.
Doesn't replace: Visual merchandising, editorial curation, brand storytelling. AI can surface the right products. Humans decide how to present them. The agent is a shopping assistant, not a creative director.
Model cost trade-off: The example uses Claude Opus for maximum quality. In production at scale, Sonnet or Haiku may be more practical. The GROQ query generation works well even with smaller models because the compressed schema gives the model clear structure to work with. Test with your catalog to find the quality/cost sweet spot.
No semantic search in this example. This guide shows GROQ predicate queries. The agent enforces constraints. It doesn't rank by meaning. For combining structured filters with semantic ranking (text::semanticSimilarity() inside score()), that's a different pattern covered in the Semantic Search guide. The predicate approach is powerful on its own for catalogs with well-structured attributes. Most product queries are constraint-based ("under $100, size M, blue") not meaning-based ("something cozy for fall").
Pricing: Base Sanity Context is available on all Sanity plans. No "contact sales" gate. Embeddings (for semantic search via text::semanticSimilarity()) are the paid add-on through AI credits, but this example doesn't require them. The structured query capability works without paying extra.
Try it yourself
Ask the assistant: "Show me items under $100." Watch it generate a GROQ query, filter the page, and show matching products with live product cards. Then check the Agent Insights dashboard in Studio to see the conversation classified.
pnpm create sanity@latest --template sanity-labs/starters/ai-shopping-assistant --package-manager pnpm cd your-project pnpm bootstrap pnpm dev
The bootstrap script imports sample products, categories, brands, and a Sanity Context document into your into your dataset; all you'll need is an Anthropic API key. A handful of products with different attributes (sizes, colors, price points) is enough to see the agent generate meaningful queries. You can add more products in Studio at any time.
Go here for the full Sanity Context documentation.
More in this series
This guide is part of AI Content Operations, a series on building AI-powered content workflows with Sanity.
- AI Translations: Store glossaries and style guides in Sanity, feed them to the Agent API at translation time
- Content Audits: Automated content quality checks using the Agent API