What agents need to operate your content
What developers doing agentic engineering need to know about what it takes to run content ops for real businesses today.

Knut Melvær
Principal Developer Marketing Manager
Published
Agents became content operators this year. On our MCP server, agent activity grew 70 times over in eight months, we recently published a report on it. Barely two months later, at the time of writing this, it has grown to about 2.5 million tool calls from 20,000 organizations, and counting.
And this work is not the greenfield writing of AEO optimized blog posts that the LinkedIn feed will make you believe. What we saw in the report is that 91% of it is operations on content that already exists: auditing, editing, publishing, migrating, translating. (These are teams already on structured content, so read it as what agents do once they can reach content, not as a census.)

Our conversations with customers have moved the same way. Agents come up in roughly one call in four now, up from about one in twenty last fall. And nobody on those calls asks whether the CMS is dead. They ask how to keep a support chatbot from inventing prices, how to automate updates to pages bound by regulation, how to move decades of documents out of a legacy system, and how to run translations efficiently and correctly across a dozen markets.
These are operational questions, from teams whose agents are already in the content. And not-so-humble brag: we’re now winning contracts because we’re seen as one of the most AI-forward content platforms on the market. Not because we show up to meetings with lofty claims and fancy slides, but because we are able draw the line between the everyday challenges and what you can employ agents and LLMs to do for you.
Putting content into Markdown misses the point
Thus, I find it frustrating that the answers circulating in developer discourse are much thinner than that. Takes like “put content in markdown files and let agents grep.” Or… “load all the content into a vector database and let them retrieve by similarity, bob’s your uncle.” Sure, but then what?
What I don’t find in these takes are reflections on how that content travels through an organization, or what happens with time, complexity, and scale. How different parts of your content corpus need different types of governance. And so on. The many business problems that require actual engineering.
That being said, these takes often come from a shared frustration. They come from developers who got stuck in a web CMS that was built for publishing pages, but doesn’t work well with agents. We all are starting to feel how antiquated software feels when you can’t hook it up to your Claude Code, Codex, Pi, or whatever you’re using this week.
But the alternative solutions throw away most of what it takes to operate content, which is more than a place to write and read it from singular or few technically-minded operators. To solve the content problems most modern businesses have with AI you need a live backend that humans and their agents can query, change safely, review, govern, and ship from. When GitHub barely scales for agentic engineering, how can you expect it to work for something that is at the same time often much more volatile and fluid than code?
So how did we get here? How can we elevate the conversation about agentic content operations?
The web CMS was built for pages. Content outgrew that.
What's reaching its limits isn't content management as an idea. It's the one specific machine for it, the publish-to-web CMS: a rigid content database of "posts and pages" (iykyk), an inflexible forms UI bolted on top, and a one-way pipeline whose whole job is to push the result out to a website. The whole thing assumes content equals web pages, edited by humans clicking through forms, rendered to one destination.
Most headless CMSes claimed to escape this hatch, but when you opened the hood you'd still find content stored as HTML blobs, loads of "page"-bound assumptions, and so on. Which isn't strange. It makes the conversation with customers who already thought this way much simpler. But for the last decade, we have made a lot of business on helping customers out of the limitations this approach has when you need your content to do more and for content ops to be automated.
Content as a collection of web pages just didn’t help them into the future.
We are post pages now
So now that every part of that founding assumption has given out, so the machine built on it has to change. That's actually why Sanity was made in the first place. We built it to hold the content of OMA.com in a way that fit their business, which was architectural projects with loads of metadata. Content is not pages. It's product records, pricing, specs, legal language, support answers. It's the structured data an app reads, an email assembles, and another agent queries to do its job. A page is one way content gets rendered, not what it is. And humans clicking through forms is no longer the only way it gets operated on. Agents do it now, on behalf of those humans, at a scale and speed no forms UI was built for.
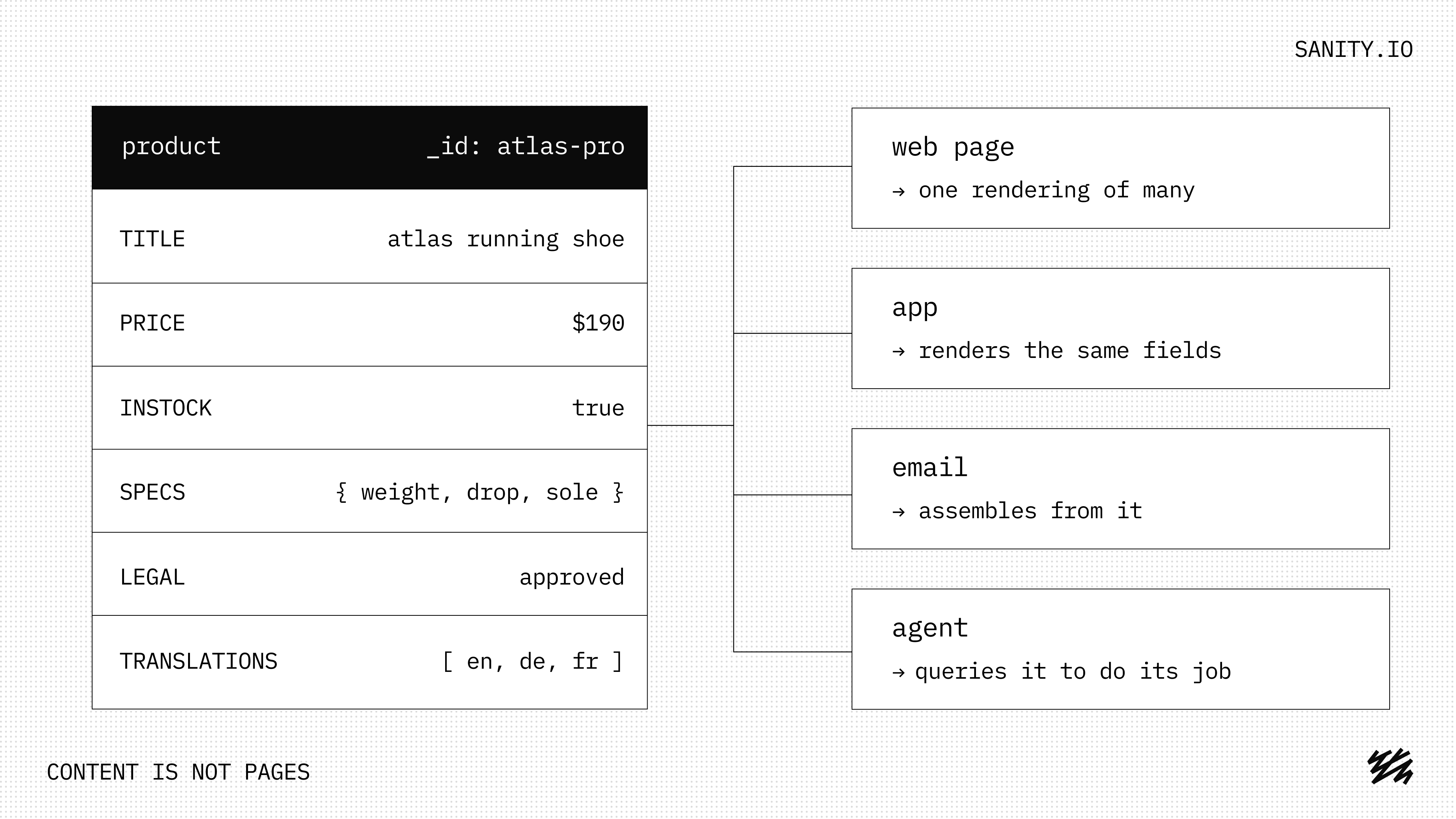
The future showed up on schedule. The web still has "pages" you can address with a URL, but conversational interfaces are viable now too, and what happens on a single "page" keeps getting more complex: multiple states, single-source-of-truth content pulled from several places, the same content wanting to show up in other channels.
Meanwhile the publish-to-web CMS came with API limits that make it impractical to script against, document locking, and a backend where it's hard to tell who changed what when the change never trickled through a UI. That's not an environment agents thrive in.
So on the symptom, the markdown-in-git crowd, the vector crowd, and I agree: this machine has run its course. We disagree about why, and about what it should become. The web CMS was already straining before AI, and the answer isn't to rebuild it on top of git or a vector database. It's to let it evolve into what humans and agents actually need now.
And that changes the job. If content is more than pages, and agents operate it alongside people, then the thing you're choosing has a narrow, specific job: make it easy for humans and their agents to operate on content. Not to store pages. Not to render a website. To be the place the work gets done, by whoever (and whatever) is doing it.
That takes a set of platform primitives that work together and can be shaped into systems that fit how agents and humans actually work.
Who decides where content lives?
If you're the developer reaching for markdown or vectors, notice whose problem you're solving. A clean repo with no content management UI is a great developer experience, and the frustration with systems that never gave developers one is earned. What developers actually want is a CMS-equal experience for code-shaped work. Content they can version, type, query, and script against with the same fluency as the rest of their stack, without clicking through someone else's forms or having to build new stand-alone applications alongside the CMS thinly veiled as “plugins.” What they want is legitimate. Markdown in a repo just happens to be the nearest thing lying around that delivers it. And to be fair, coding agents are pretty great at git (which is weird because few of us were. Maybe they just actually read the docs).
Content ops is deeply cross-functional
But content operations is not a pure developer function. It is an org function, and the companies that get this right treat content as a business asset, not (just) a marketing one. The product page, the help center, the localized variants, the legal language that has to be exact, the campaign that spans a dozen surfaces. These get operated by editors, localizers, marketers, compliance, the next engineer who inherits the repo, and the agents acting for all of them.
None of those people are in the room on the quiet afternoon a developer decides content is just files now. They find out the next day, when they're told to make a GitHub account to view the diffs of what the agent did and wait for the preview deployment to clear the CI/CD pipeline.
And if they don’t want this, sure, you can vibe code them a dashboard and an MCP and stuff. But now you are building the thing you tried to get rid off in the first place.
What your content platform needs
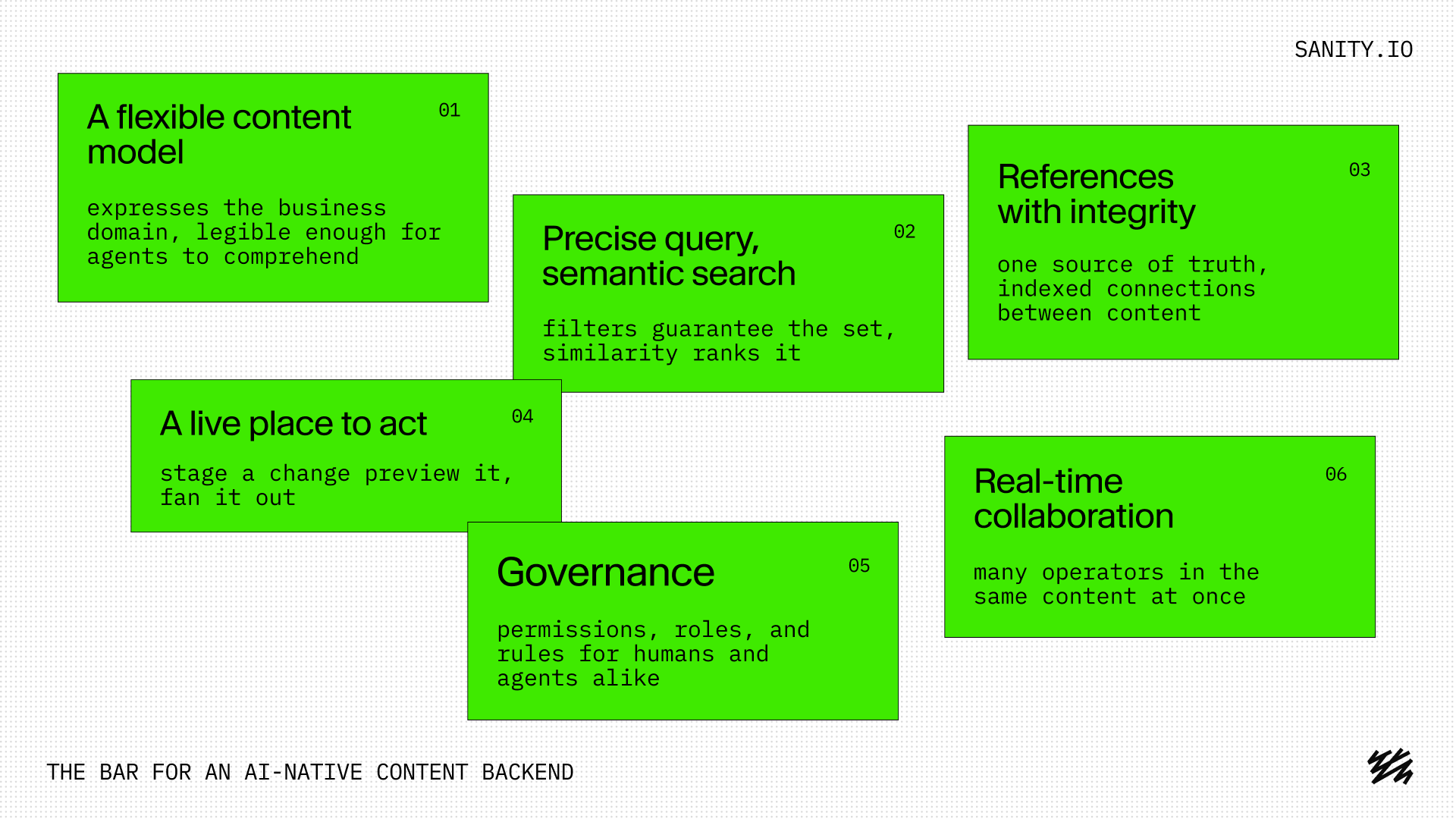
So the test is not "can an agent touch this." It can. The test is whether the thing you pick makes content easy to operate, over years and across people and their agents. It should meet these probably tip-of-the-iceberg platform requirements:
- A flexible content model that express complex business domains that agents can read and comprehend
- A way to query precisely and search semantically
- A way to express content dependencies by relating content with referential integrity
- A live place to act, where a change can be staged, shown for what it actually is for a human, previewed, and fanned out
- Have governance, permissions, rules for human and agentic operators
- Support concurrent, real-time collaboration
Hold your choice up against those.
Two shortcuts, one mistake
Markdown-and-grep and vectors-and-similarity look like opposites. But they make the same move. Both flatten content into a single primitive, a file or a vector, and swap structure for fuzzy retrieval: lexical in one case, semantic in the other. Neither can answer the questions content operations actually need to ask.
A content team asks for every product over $100, in stock, not yet translated to German, newest first. In structured content that is a query:
*[
_type == "product"
&& price > 100
&& inStock
&& !("de" in translated)
]| order(_createdAt desc)Grep cannot express that. Neither can cosine similarity; "close to a German translation" is not "missing one." Sure, you can probably cast the net wide enough to get all possibly relevant content and then have the agent execute some python to narrow it down based on regex matches, executing some ad hoc Python code, and whatnot. But now you have spent seconds or minutes and compute something that a database solves in milliseconds, multiplied with every time this information needs to be retrieved.

An agency we spoke to that built three customer-facing agents on structured content (a shopping concierge, an editorial QA agent, an embedded services assistant) landed on the same point from the build side. By combining GROQ features like hard filters with semantic ranking in one query means the constraint is guaranteed. Similarity can rank what comes back. It cannot promise that everything that comes back passes the filter. And when the underlying fact changes, structured content changes once.
Having that content in Markdown means editing every file the fact got copied into. The vector store as content backend has no single source of truth to edit at all, so "update the price everywhere" becomes "re-embed and hope." We wrote up the markdown version of this in detail when Cursor moved off Sanity, so I will not relegate it here. The short version is that the moment you need to query or update content as a set, you start rebuilding the database you just deleted.
Structure is the efficiency play, not the tax
The “just put content into a vector db” camp has a sharper version of its case, and it deserves a real answer. Structure, it says, was always scaffolding: the metadata, taxonomies, and markup we bolted onto content so dumb computers could route it. Now that models read raw text, the scaffolding is dead weight. Embed everything, let the model sort it out, skip the modeling. Done deal, 2030s, here we come!
The grievance underneath is correct. Hand-building taxonomies and tagging markup was expensive and brittle, and a lot of old CMS work was exactly that toil. The conclusion is backwards on three counts. And not going to lie, I find it somewhat surprising that this is a real stance we have to address at all. Because you don’t need to scratch the surface much before you start to see the cracks in the argument.
First, efficiency. Embedding a whole corpus, running a model call per retrieval, and packing the results into a prompt is the expensive and flimsy path, and the cost climbs with scale. The research on long context is blunt about the ceiling: accuracy drops as you cram more into the window, even when the relevant tokens are sitting right there, and you pay for every token on the way down. A query against a model returns what you asked for and nothing else.
The above-mentioned agency measured this in production: a compressed schema summary in the system prompt, a step cap, and caching cut their cost per agent turn by an order of magnitude, because the agent stopped re-fetching things a legible model had already told it.
Second, the labor. What made structure painful was the manual tagging, and that is exactly what agents now do for you. Look back at what those 1.46 million calls were: migration, metadata, SEO, translation, governance. Agents are generating the structure the old workflow made humans produce by hand. Structure did not get more expensive. It got cheap. So yes, agents are great for structuring content with your instructions for what that structure needs to express. So the last good reason to keep content in an unstructured blob just left.
Third, whose structure? Sure, agents can infer structure from content and recognize stuff like product descriptions, price, etc. But this inference is fairly ad hoc and does not necessarily map to what the business or domain of that content repository is about. “But Knut, we can just solve that with prompt and agent skills!” Sure, but that is just free-text content modeling. You're back at the thing that you tried to get rid of.
Structured content is the baseline. It makes content legible and queryable. Operating it takes everything a real backend does on top.
Where agents are weakest is where content ops lives
There is a hard limit to what prompting and skills paper over, and it sits right on the part of content operations that matters most.
I have made plenty of smaller sites where I even hoped to stay clear of adding a content backend and just rely on markdown and JSON files. In my experience, despite my insistence in AGENTS.md and skills and prompting, agents will struggle with keeping even smol samples of content in sync. If precision is key, like when you report anything that has to do with numbers, then you're in for a ride.
Maybe that is a skill (pun int.) issue on my part, but at the same time, if anyone cares about consistent content across surfaces, I must be one of them, having been in that business for at least a decade. So if I struggle with this, I expect that struggle to be real for others too.
Agents are strong on a single, contained change. On changes that have to stay consistent across many places at once, they fall off a cliff. The coding benchmarks show it cleanly: the best models clear about 70% on isolated, single-issue tasks and drop to roughly 23% to 25% when the task spans many files, a result replicated on long-horizon, multi-file work. Hand them a structured surface instead of raw text to string-match against and the failures shrink fast; in one study a weak model's rate of giving up and returning an empty edit fell from 46.6% to 7.2% once it worked on structure instead of flat text. Code is the format these models were trained on hardest. If structure beats flat files there, it beats flat files for your content by more, not less. Plus: Code is easier to correct for with compilation, types, and tests.
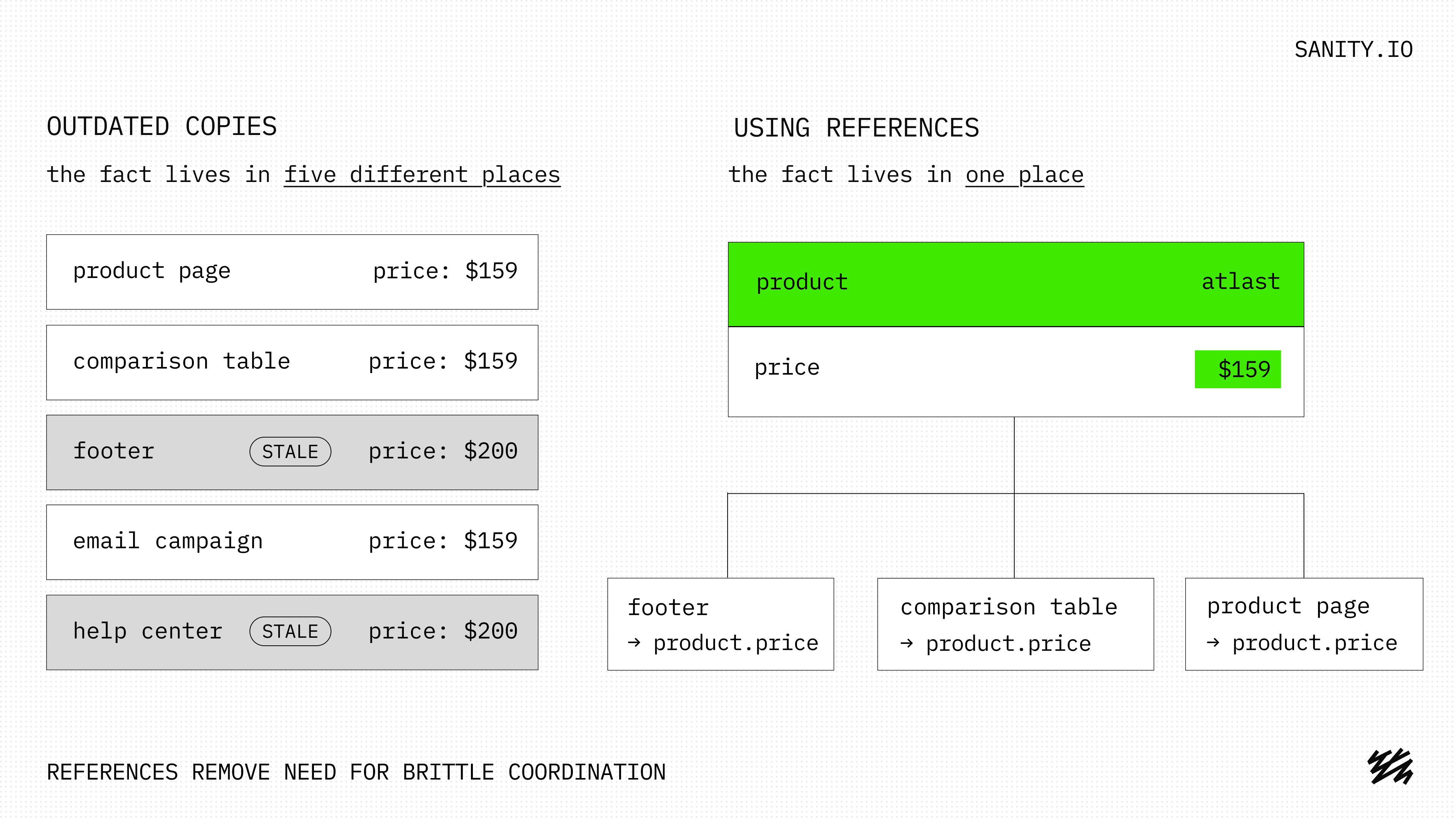
Keeping a product's positioning consistent across the product page, the comparison table, and the footer is the same shape of problem as a coordinated edit across many files. It is the regime agents are measurably worst in. Prompting agents into consistency suddenly costs more work and more tokens than keeping the content as a single source-of-truth object in a database and using the tokens at letting the agent update that.
Even if models get better at this every month, can't we expect that the gap closes on its own? It won't, and references, that is, indexed connections between pieces of content, are why. References don't make the agent better at coordination; they remove the need for it. When the comparison table and the footer point at one product document, changing the product changes both, because they were never separate copies to reconcile. That is architectural, and it holds no matter how good the model gets. "The agent will grep carefully," or "similarity search will catch every affected chunk," is a bet on the model being clever enough this quarter. Designing the problem out beats betting it away.
A backend humans and agents can operate in
So far we have seen that agents need a model that they can comprehend, precise queries plus semantic search, references with integrity. They also need an operating surface. Where they can act, while we have governance over who and what may do what, and a room for many operators in the same content at once. That's exactly where a markdown repo and a vector store have nothing to give, and each affordance below matters as much for the person reviewing the work as for the agent doing it.
A live backend
A real content backend is live. Someone makes a change, agent or human, and it is immediately the truth that every other agent, every editor, and every surface reads, with no commit, no rebuild, and no stale copy to re-embed. Several people and agents in the same content at once is the case every real-time collaborative tool was built for. Google Docs and Figma refused the version-control merge model because line-based merge and last-write-wins lose work when edits collide. Agents editing concurrently are that case, multiplied. Sanity was launched with this model in 2017, and since then we have added full attribution and atomic reversion capabilities to any change that comes through the API (which are all them changes).
Content as objects, not blobs
Modern content is composed of objects: typed blocks with marks, annotations, and references (Portable Text, in our case). An agent operates on one block, field, or annotation instead of find-and-replacing a wall of text, and a person can see exactly which object changed. Markdown had to be reinvented as MDX or fall back on HTML to express stuff like this, with the trade-offs to portability that comes with. With Portable Text, you can still keep markdown as an input and output format, alongside all the others.
Interestingly, we see a new content genre that requires this: system prompts for agents. Store the system prompt as a content object and human editors can use a WYSIWYG editor to add conditional clauses and tune the agent's voice without requiring a code deploy, allowing for much more rapid iteration. Our agency above did exactly that, and an enterprise customer recently asked for the organizational version. They want the whole company to contribute to prompt writing, product managers included. The instructions that steer an agent are content too, and they need the same review, versioning, and rollback as everything else.
Staged, scheduled changes
A coordinated change across 40 documents should not be 40 live edits you hope land together kinda at the same time. Handling concurrent releases shouldn't require humans and agents to reason about git rebasing and merge conflicts. With Content Releases, an agent stages the whole change as one set, a person previews the future state, and it ships atomically at a chosen moment, or rolls back. The agent proposes, the human approves, the system ships. And it doesn't require you to set up and orchestrate a cron job that reads a YAML value and tries to merge a PR.
Governance for humans and agents alike
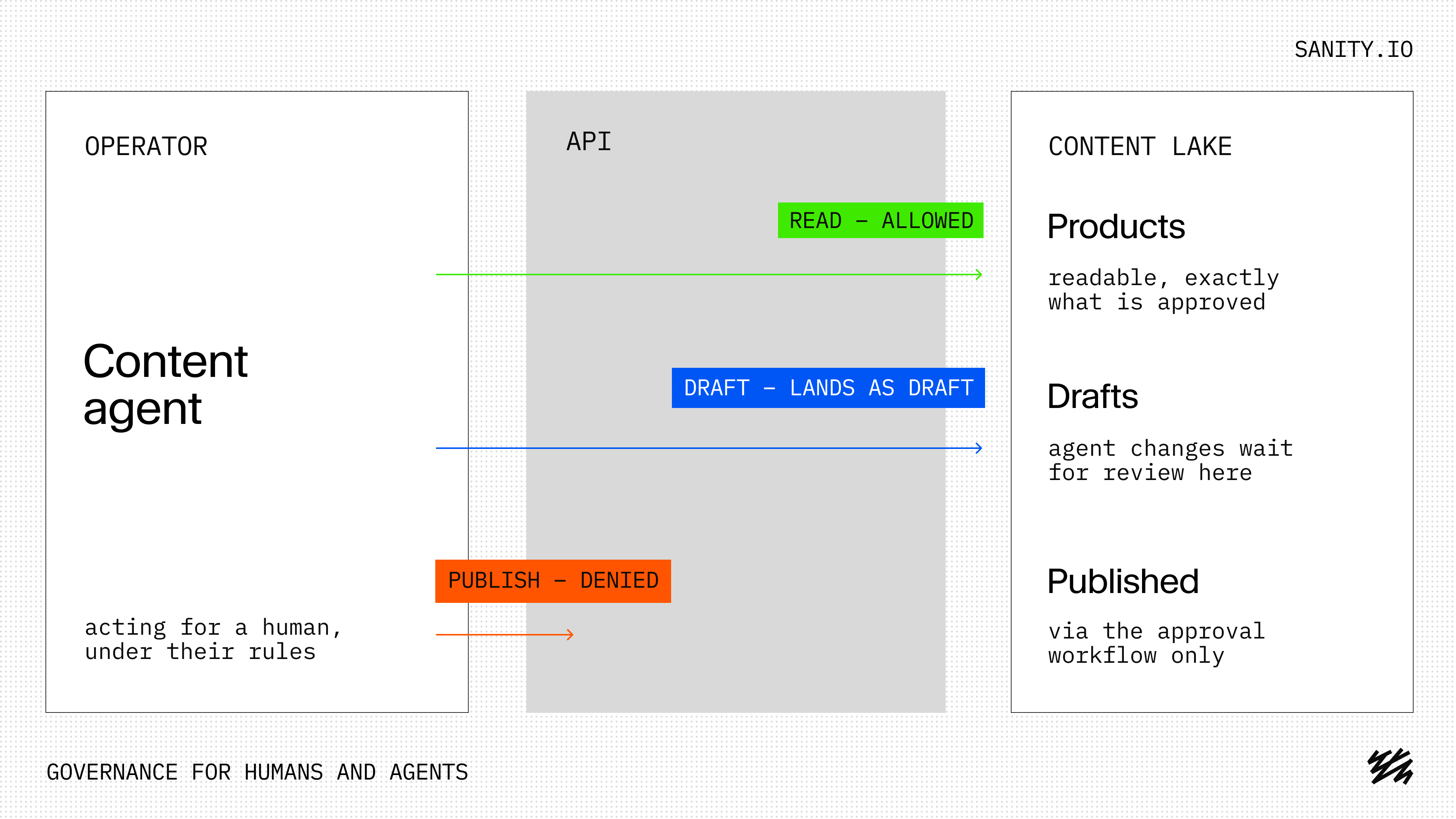
As Claude would put it, content is often load-bearing in that it describes how your business exists in the market. From product descriptions to the legal pages that define your customer relations. Business-critical systems and content comes with the need for governance. This is what GitHub offers for code changes. But that system doesn’t translate well to content.
Permissions, roles, and rules have to apply to agents the same way they apply to people, and the system has to enforce them at the API, not in the prompt. It's the loudest theme in our customer conversations right now, and the asks are specific. Teams don't ask whether the agent can edit; they ask how much it can edit in one go, and they want roles scoped so one prompt can't rewrite the whole catalog. They want mass changes to land as drafts inside the approval workflow they already have (the compliance gate applies to agents too), the public-facing agent reading exactly what's been approved for it and nothing else, and spend limits that ask before the big run rather than after.
A git repo can protect a branch, and a vector store can gate an API key. Neither can express "this agent may read products, draft price changes, and publish nothing." That sentence is a content permission, and you need a backend that speaks it.
Sure, you don’t need this for your personal blog, but you would be surprised how soon this becomes a concern in even smaller teams, especially if they have a successful business.
Reactions that don't live in a prompt
Functions handle the mechanical fan-out. A content change triggers validation, enrichment, or a downstream sync automatically and deterministically. The agent does the part that needs judgment, the system does the part that needs to be reliable. That division is the real answer to "there is only so much you can do with prompting." You do not put the guarantees in the prompt to a non-deterministic model. For the same reason you prefer typed languages with agentic engineering and tell the agent to write tests, and tell it strictly not to delete the test to let the CI/CD step pass.
Diffs and previews you can review
Because you are letting something act on your content, you have to see what it did. A line diff tells you a paragraph changed. It does not tell you a price field went from $90 to $190, or that a reference got repointed to the wrong product. Structural, field-level diffs do, and a preview shows the rendered result before it goes live. This is what makes delegating to an agent safe: a person reviews and approves in the terms of the content, not the file.
Where the boundary shows
You can watch it in practice. A team pointed an agent at a Sanity schema and let it build a services page. It chose the right page-builder blocks, got the card count right, even predicted the icons, and had a working page in about eight minutes. Then it reached images and media and stopped, and a person uploaded them by hand. The capability is real, and it is bounded by the affordances the system hands the agent. Where there was a primitive to operate through, it flew. Where there wasn't, it stalled.
Don’t put your agents in a corner
When the thing operating your content is a person and an agent acting on a model, not a person clicking through pages, the center of gravity moves from how content is presented to how it is structured and operated. The market is already reorganizing around that. Across the migrations agents ran on our MCP server, the big sources are WordPress, Webflow, and Shopify moving into structured content (markdown files account for 2%), and Salesforce is buying a content platform so its agents have something structured to assemble from. The half worth keeping was never the forms UI. It's the backend that makes content operable.
Sometimes the answer really is markdown in a repo. If your whole team writes code, your content has one destination, and you ship rarely, flat files are fine. At least for a bit. The point is to choose that against the bar on purpose, not to back into it because it was the most comfortable thing on a Tuesday.
Content Ops doesn’t scale on top of files
And be clear about what you're giving up. Flatten your content into files or vectors and you lose the query, so "every product missing a German translation" becomes a script someone has to write and maintain. You lose the single source of truth, so the price lives in five places and is right in three of them. You lose field-level diffs, so nobody can say what the agent actually changed, only that the file did. You lose staged releases, so a coordinated change is 40 live edits you hope land together. None of these losses show up on the afternoon you make the call. All of them show up later, as rebuilt tooling, as agents you can't safely delegate to, as a localizer waiting on a GitHub invite.
So before you commit the whole organization to files or to vectors, point an agent at your content and watch where it flies and where it stalls. That gap is the bar, and closing it is the job, ours and that of whatever backend you choose.
It's worth closing. On the other side of it, a launch across 40 documents is one staged release a person previews before it ships. The translation backfill that used to be an agency engagement runs as a pipeline with the glossary intact. The support agent answers from the same approved content legal signed off on, and when a price changes, it changes once, everywhere. The teams in our data who work like this didn't get there with better models. They got there in about eight weeks, by giving their humans and their agents a backend both can operate.
That's a more interesting conversation than whether the CMS is dead. The next move is yours.