Content is Data: Announcing Sanity Content Lake
Learn about Content Lake, our real-time database for structured content.

Simen Svale
Co-founder and CTO at Sanity
Published
Today, we're excited to announce the release of Content Lake, a real-time database that gives you access to your content however and wherever you need it. It is the culmination of months of engineering work, and years of iterating on a vision, that puts in place a key piece of our long-term strategy to become a unified content platform. Read on to learn more about Content Lake and the GROQ features that are included in this release.
Why we built Content Lake
We’ve been told by countless customers that they view Sanity as being the only content platform that covers their needs. We designed Sanity to free organizations from the trappings of typical content management systems (CMS) that force you to think of your content in the context of web pages and content hierarchies. Most headless CMSes have the same limitations but offer some API as if that would address the fundamental flaw of their approach. Although we hate being compared to a headless CMS, the framing is helpful when understanding why we built the Content Lake. When one examines the two components that make up a headless CMS, you have an authoring layer and a database. This post will focus on our enhancements to the database, but suffice to say that we’ve had a powerful authoring layer for quite some time.
The reason the database is so important to Sanity is due to our structured content foundation. Most platforms in our space treat content as a soup of information that is limited and defined by the format it was authored in. Sanity spearheaded a new approach to content and turned the old model on its head. Instead of thinking of the world in terms of web pages, structured content frees you to think of content as data – well-formed records that let you reshape and present your content in any format. But structured content alone doesn’t get modern organizations to where we think they need to be. A place where they can create compelling digital experiences that resonate with their audiences.
You also need a robust, open-source query language that lets you interact with your content. You need support for real-time editing and patching of your content so you can collaborate with humans (and bots!) without locking others out or accidentally overwriting their changes. You need developer tooling that feels familiar the moment you interact with it. You need the ability to transform and shape your content on the fly. You need to base your content delivery on best practices like Portable Text. Our motivation to build this ideal database comes down to a desire to move the entire industry forward. It’s what we think our customers need, and in the end, we felt we had to build it ourselves to ensure it was done properly.
We believe today’s announcement fundamentally transforms how the industry can interact with content today and in the future.
Getting it right for the launch
When we launched Sanity.io in 2017, our APIs were already real-time, patch-based, and had full revision history down to the keystroke. We knew it’d be almost impossible to retrofit it with this functionality later, so we took our time to get it right from the start. In addition, we are very, VERY serious about having APIs that don’t break. This perspective means our team needs to keep APIs, even those with inconsistent behavior, active as customers could be inadvertently relying on those inconsistencies as part of their content management workflows. This makes optimization hard and impractical. And this is a reason we have left our APIs mostly untouched since our launch several years ago.
Enter Content Lake. The Content Lake is the database that we’ve rebuilt from scratch over the past 10 months. We've reimplemented parsers and query planners to create a faster, more consistent solution that is easier for us to optimize. Starting today, the Content Lake is available to all Sanity customers.
API versioning
As mentioned we really don’t like to make API breaking changes. That's why we are introducing API versioning to ensure that even as we fix bugs and release new features, customers relying on our platform can offer the same great experiences to their users while they decide how and when to migrate to the new versions of our APIs.
Our API versioning approach is pretty straightforward. Like the convention followed by Stripe, all Sanity endpoints are now versioned on ISO-dates:
The following query URL uses API version 2021-03-25:
https://example.api.sanity.io/v2021-03-25/data/query/production?query=*It’s worth mentioning that there is also an experimental endpoint vX that gives you early access to beta features.
Update your existing client configurations to reference the new APIs (more information can be found in our documentation) and get access to new features. If you do nothing, you’ll just continue to get the current version (v1).
New functions for GROQ!
A summary of the new features and functionality we are releasing as part of this Content Lake announcement is below. Remember, to get access, you’ll need to update your clients to reference the new versioned API endpoints.
Namespaces
This release brings function namespaces to the Sanity APIs. In addition to the default global namespace, this release introduces two new namespaces to GROQ functions: pt for portable text functionality and geo for geospatial queries.
Boosting, scoring, and plain-text
Need to weigh the return from a search query? Now you can. Give emphasis to matches on certain fields or mentions of strategic initiatives.
score()- takes an arbitrary number of valid GROQ expressions and returns a numerical score, which can be used to sort and filter items in an array.boost()- create a sense of weight in a scoring algorithm. It accepts two arguments: an expression and the amount to boost the score if the expression returns true.
In addition, if you want to use boosting and scoring along with Portable Text you can now match against
pt::text()- a GROQ filter that returns a plain-text version of a Portable Text-field
Geospatial search
geo(object)- accepts an object as a parameter and, if possible, coerces the value to a geo-type document by a set of rules.geo::latLng(latFloat, longFloat)- creating a new geo object for a singular point. Returns a geo object from the latitude and longitude floats provided.geo::distance(geo-point, geo-point)- takes points and returns a numeric value for the distance between in meters.geo::contains(geo-value, geo-value)- returns true when the first geographic geography value fully contains the geographic geometry value.geo::intersects(geo-value, geo-value)- returns true when the two areas overlap or intersect.
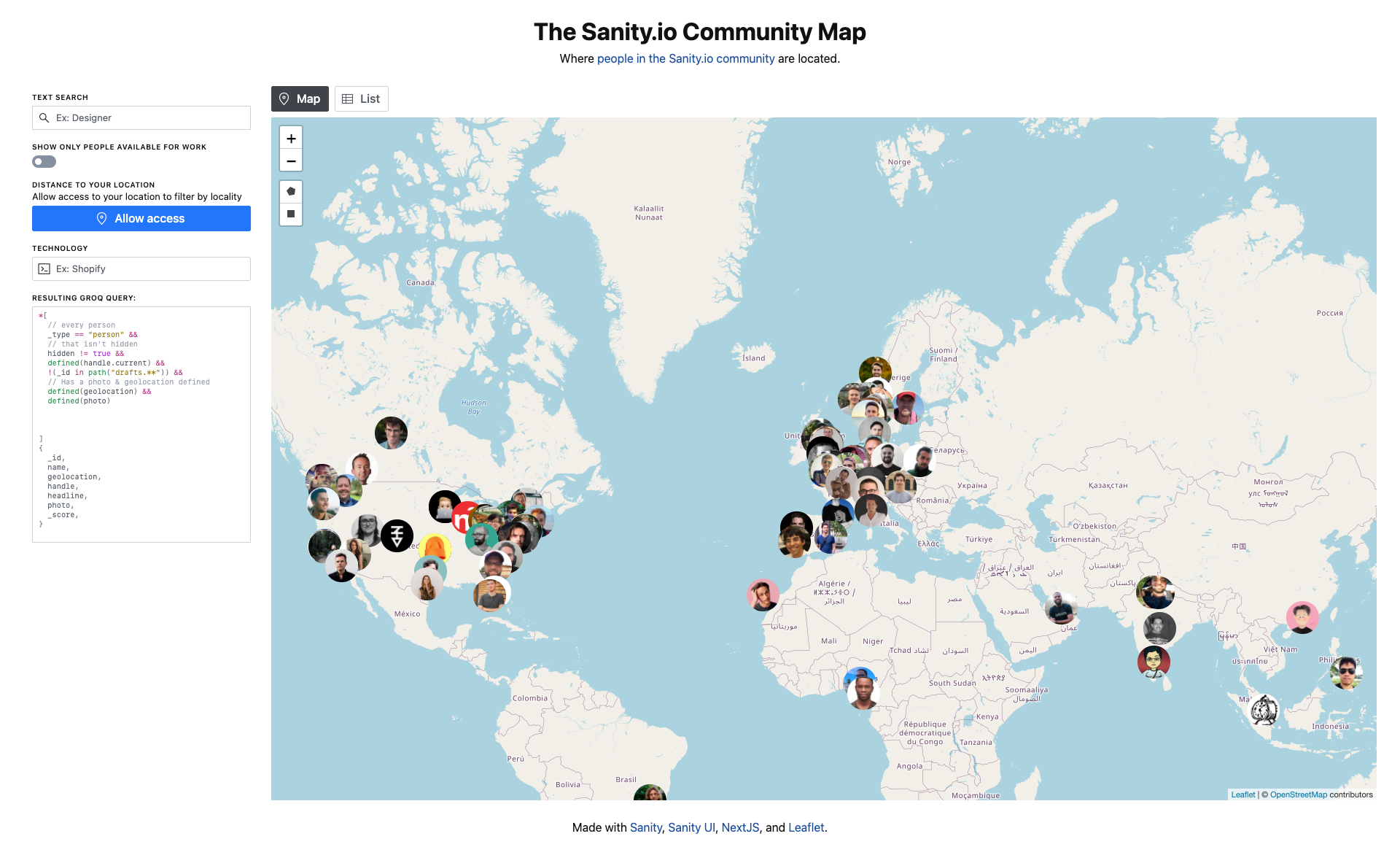
Demo: The Community Map
To demo these new features, we put together a community map that lets you look for profiles by location, strings in their description, and technologies they have referred to.
Check out the map and the code.
We’re thrilled, perhaps even stoked, to be releasing the Content Lake and are looking forward to the creative digital experiences these new features will empower you to build.