Localization
Localization allows you to deliver your content in different languages for your users.
Localizing UI vs localizing content
This article is about how to localize the content you manage in Sanity Studio. To learn about how to change the UI language of your studio, visit this article, or visit this article if you want to learn about adding internationalization to your plugins.
Best practice
Localization in Sanity is performed by storing language data as a value of a field in a document.
We recommend using these two optional plugins to simplify creating and maintaining localized documents and fields in Sanity Studio.
- For translated documents, we recommend the @sanity/document-internationalization plugin, which will relate translations as references and handle setting a “language” field value on documents.
- For translated fields, the internationalized-array plugin can be used with any field type and scales to as many languages as you may need to author.
Methods of localization
Sanity allows you to model translated content as it makes the most sense to your workflow and content structure. There are two main approaches:
- Field level localization
- A single document with content in many languages
- Requires you to publish content in all languages simultaneously
- Achieved by creating an array that generates a field for each language value
- Best for documents that have a mix of language-specific and common fields
- Document level localization
- A unique document version for every language
- Allows the option to publish each language version independently
- References join language versions together
- Best for documents that have unique, language-specific fields and no common content across languages
- Best for translating content using Portable Text
Your preferred method will depend on your use case, content model, and publishing workflow. Each document’s schema plays a role in deciding the appropriate localization strategy, so you may use both in a single project.
We offer simple plugins for both strategies to improve the authoring experience in Sanity Studio.
Sanity Studio walkthrough
Example repository
This Course Platform Demo is a Sanity Studio and Next.js front-end showcasing internationalized schema, popular plugin configuration, and how to query for localized content.
Field-level translations
Localized arrays
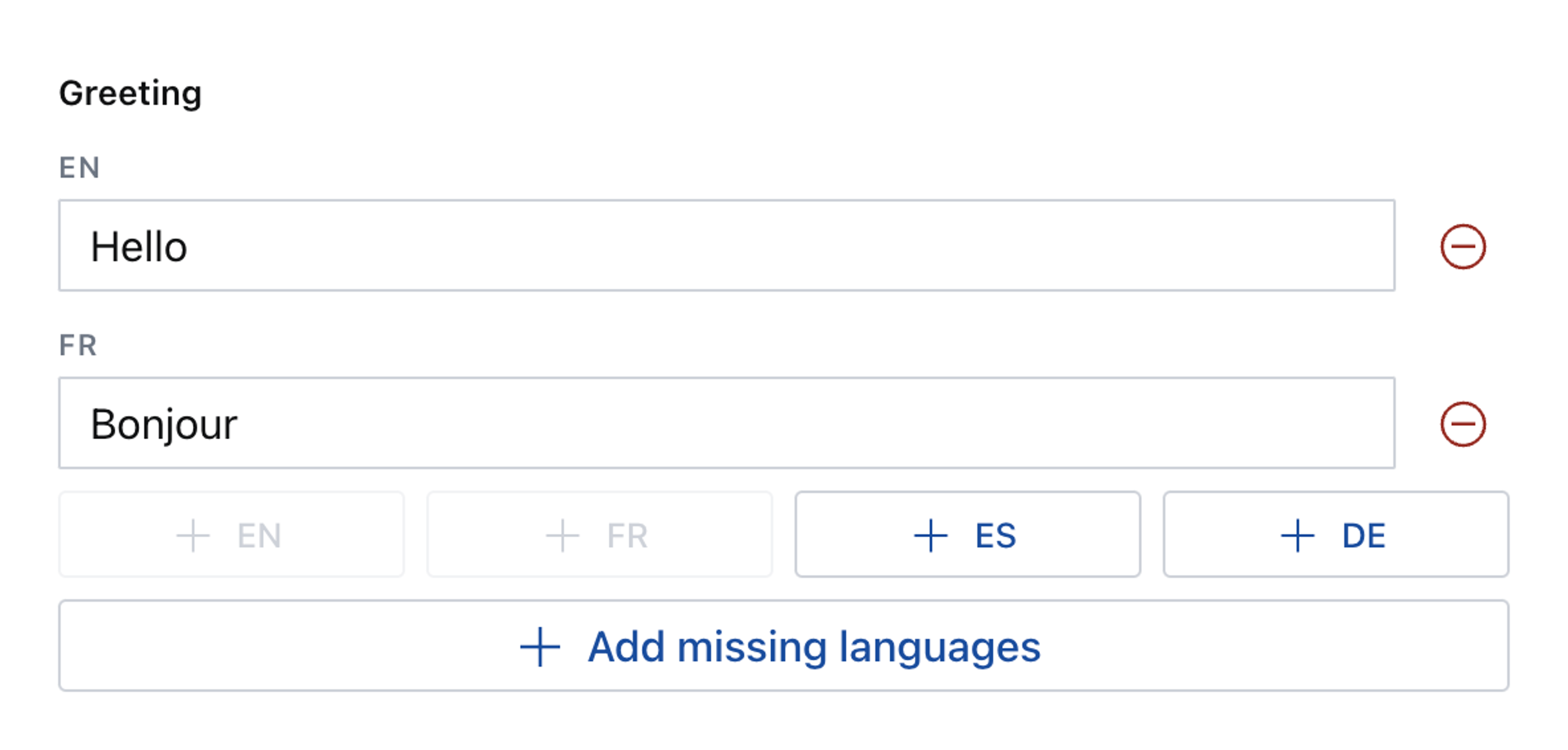
You may prefer to create localized fields in an array structure for projects with many languages. Arrays use fewer unique attributes than objects using this method.
Here is a quick explanation of how language objects impact attributes.
An object for a string field with three languages creates these attributes:
title title.en title.fr title.es
You create another unique attribute in your dataset for every new language you add.
An array of objects to store both a language and field value could create attributes like this:
title title[] title[]._key title[].language title[].value
Using the language field to store the language and value to store the field’s content, you can add many more languages without using more attributes.
The built-in array component is not best suited to authoring like this – as every array item needs to open in a popup dialog – but there is a solution.
Plugin for localized arrays
The internationalized-array plugin has a custom UI that can be used for any field type and renders each field input without a popup dialog.
It stores the language in a language field.
Querying localized arrays with GROQ
Now performing the same query for name and title but with the title stored in an array, using the internationalized-array plugin.
*[_type == "presenter"][0]{
name,
title
}You will receive this data:
{
"name": "Rune Botten",
"title": [
{
"_type": "internationalizedArrayStringValue",
"_key": "IW92vi98KcGFhIzeUDasfasxu",
"language": "en",
"value": "Rune is a solution architect at Sanity.io"
},
{
"_type": "internationalizedArrayStringValue",
"_key": "IW92vi98KcGFhIzeUDagasxu",
"language": "es",
"value": "Rune trabaja como arquitecto de soluciones en Sanity.io"
},
{
"_type": "internationalizedArrayStringValue",
"_key": "Edafwevi98KcGFhIzeUDkxxu",
"language": "no",
"value": "Rune jobber som løsningsarkitekt hos Sanity.io"
}
]
}To avoid over-fetching, update the query to:
- Filter this array to just the language field
languageyou need - Only return the
valuefield
*[_type == "presenter"][0]{
name,
"title": title[language == "en"][0].value
}Now the returned data is filtered down to just what you need:
{
"name": "Rune Botten",
"title": "Rune is a solution architect at Sanity.io"
}You can use the coalesce() GROQ function to fall back to another value if the targeted one is not yet set:
*[_type == "presenter"][0]{
name,
"title": coalesce(
title[language == "en"][0].value,
title[language == "nl"][0].value,
"Missing translation"
)
}For the most flexibility, use variables so that your query remains the same but will adapt to whichever parameters you pass into it.
*[_type == "presenter"][0]{
name,
"title": coalesce(
title[language == $language][0].value,
title[language == $baseLanguage][0].value,
"Missing translation"
)
}Document-level translations
You might have more complex publishing workflows that field-level translations are too simple to solve. You could be working in a base language and want to publish that content as soon as it is ready, then publish translations as they become available from other editors or external translation services. Or you may have content that exists only in a certain locale. It might make the most sense to model localized content as separate documents.
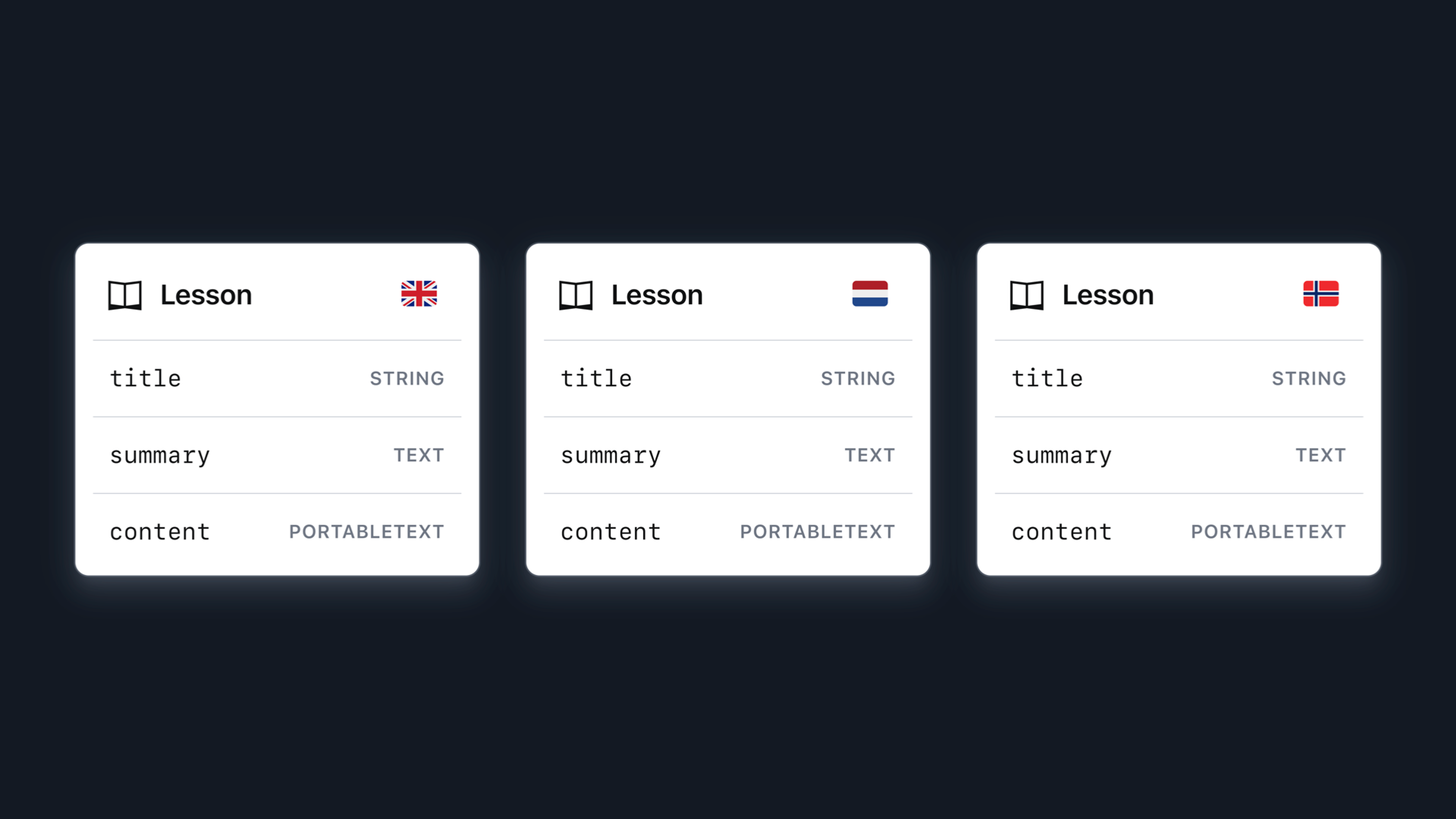
In this example, we have a lesson document type where every field is unique to that language variant, so it makes sense to store them as separate documents.
Schema for document-level translations
The simplest way to achieve this is to have a language field on documents and set this to whichever language the document's contents correspond to.
// ./schemas/articleType.ts
import {defineType, defineField} from 'sanity'
export const articleType = defineType({
title: "Article",
name: "article",
type: "document",
fields: [
defineField({
name: "language",
type: "string",
options: {
list: [
{title: 'English', value: 'en'},
{title: 'Spanish', value: 'es'}
]
}
}),
defineField({
name: "title",
type: "string",
}),
defineField({
name: "body"
type: "array",
of: [{type: 'block'}],
})
]
})You can then filter queries for specific locales, thus only presenting the relevant localized content in your front ends.
Using our Document Actions API you can further add actions in the Studio for duplicating a document into another locale and then translate the content manually.
Or use GROQ-powered webhooks to send the document off to a third-party translation service through their API for automated or professional translation. Once the translation is complete, you can re-import it to your Sanity dataset via, for example, a webhook triggered by the translation service.
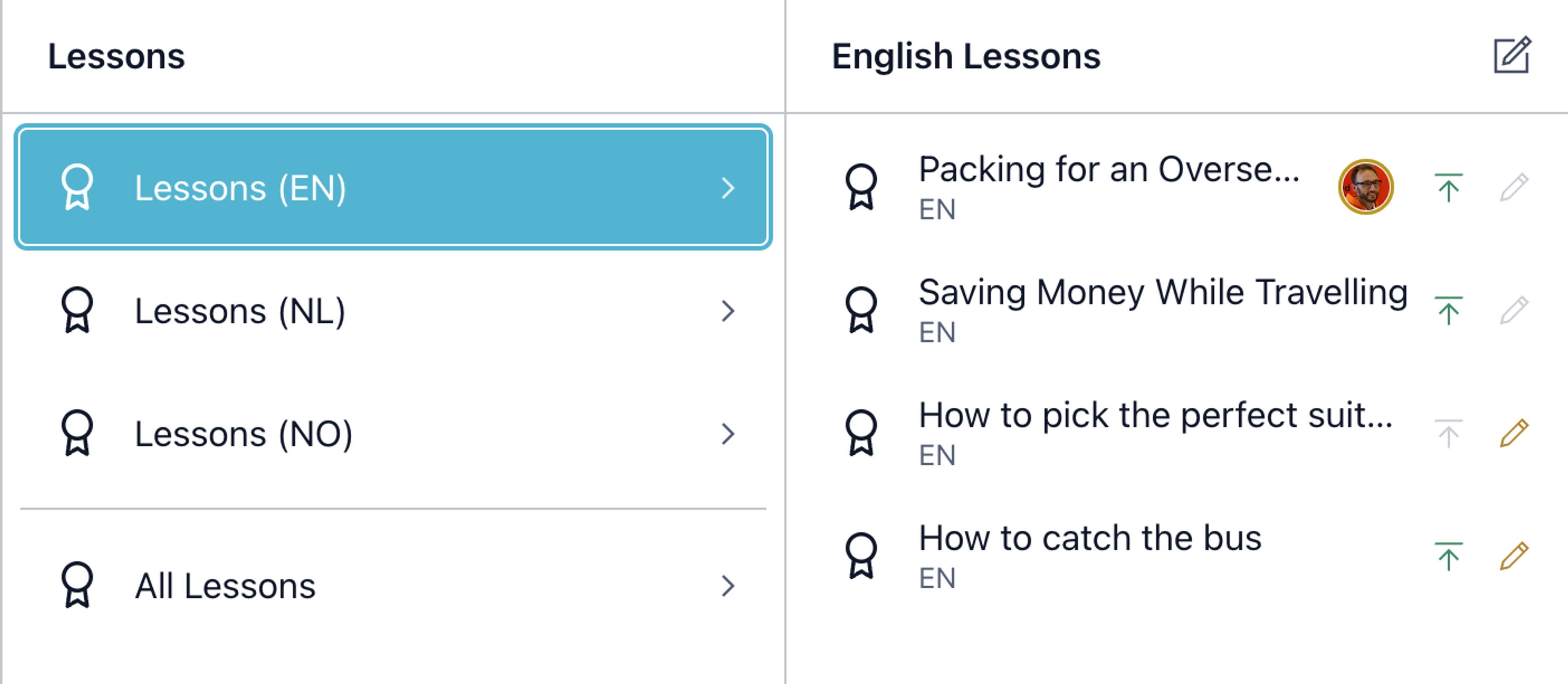
You can also use the Structure Builder API to provide segmented navigation to find and organize localized content in the Structure tool if you wish.
Plugin for document-level translations
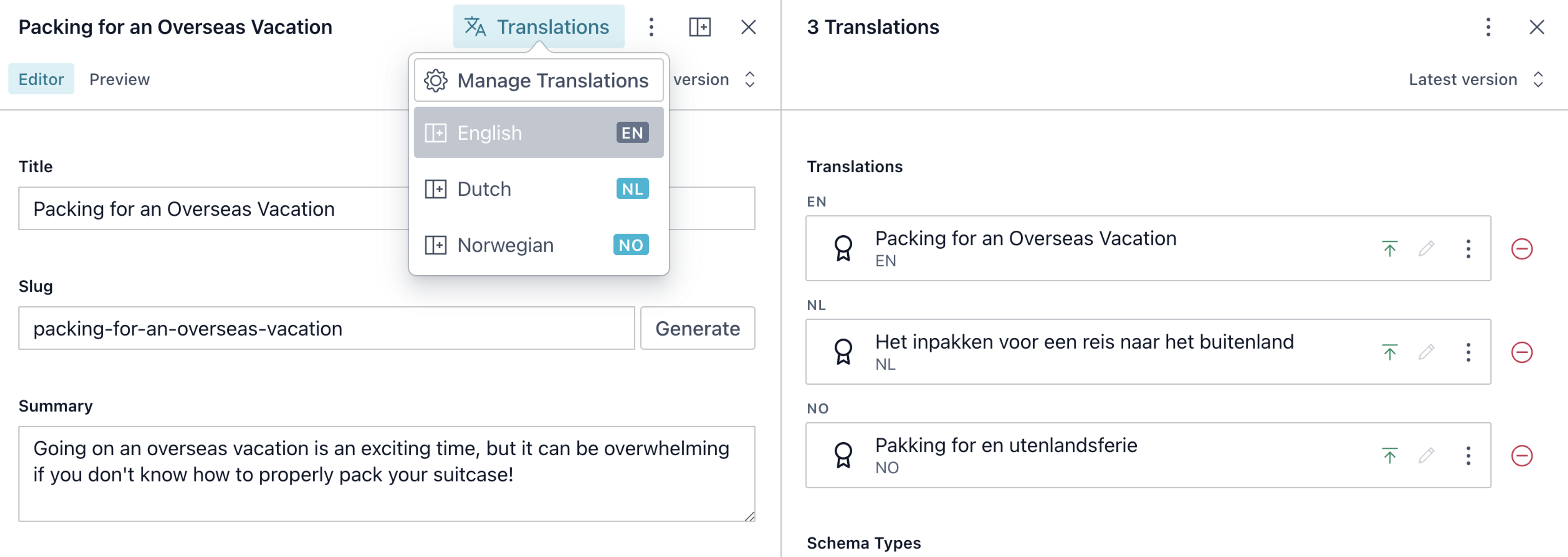
An integrated solution is to install the @sanity/document-internationalization plugin, which provides most of the above in-Studio features with minimal setup. It handles setting a language field on documents and automatically creates a linked document that stores the translations together so they are more easily queried.
Querying for localized documents with GROQ
How you query for translated documents will depend on how you have built references between them. If you use the @sanity/document-internationalization plugin, your query will look like the one below.
In this query, you are looking for a lesson type document of a specific language, then find the translation.metadata type document which contains a reference to it and other language translations.
*[_type == "lesson" && language == $language]{
title,
slug,
language,
// Get the translations metadata
// And resolve the `value` reference field in each array item
"_translations": *[_type == "translation.metadata" && references(^._id)].translations[].value->{
title,
slug,
language
},
}The plugin’s page contains more details on how to query for translations in both GROQ and GraphQL.
Translating content with the AI Assist plugin
The official AI Assist plugin for Sanity Studio offers Large Language Model-powered content translation at the click of a sparkly button.
Translation service plugins
In addition to plugins to assist with authoring localized content in Sanity Studio, we offer some adapters to popular translation service providers:
Customizing the internationalized array plugin
The sanity-plugin-internationalized-array plugin supports several configuration options beyond the basic setup. This section covers the most common customization patterns.
Load languages from an external source
Instead of hardcoding a language list, you can load languages dynamically from an API or from documents in your dataset. Pass an async function to the languages option:
// sanity.config.ts
import {internationalizedArray} from 'sanity-plugin-internationalized-array'
export default defineConfig({
plugins: [
internationalizedArray({
languages: async () => {
// Fetch from an external API
const response = await fetch('https://example.com/api/languages')
return response.json()
},
// Or load from documents in your dataset:
// languages: async (client) => {
// return client.fetch('*[_type == "language"]{id, title}')
// },
fieldTypes: ['string', 'text'],
}),
],
})Filter languages by market
Use the select option to let editors filter the available languages based on a market or region. This is useful when different markets use different subsets of languages:
internationalizedArray({
languages: [
{id: 'en', title: 'English'},
{id: 'fr', title: 'French'},
{id: 'de', title: 'German'},
{id: 'es', title: 'Spanish'},
],
select: {
options: [
{title: 'Europe', languages: ['en', 'fr', 'de']},
{title: 'Americas', languages: ['en', 'es']},
],
},
fieldTypes: ['string'],
})Configure the add language button
Control where the "Add translation" button appears using the buttonLocations option. Available locations are field (below the field), unstable__fieldAction (in the field action menu), and document (in the document actions):
internationalizedArray({
languages: [...],
fieldTypes: ['string'],
buttonLocations: ['field', 'unstable__fieldAction'],
buttonAddAll: false, // Hide the "Add all languages" button
})Complex field types
The plugin supports complex field types including Portable Text, references, and custom objects. Add these types to the fieldTypes array:
internationalizedArray({
languages: [...],
fieldTypes: [
'string',
'text',
// Portable Text (block content)
defineField({
name: 'blockContent',
type: 'array',
of: [{type: 'block'}],
}),
// References
defineField({
name: 'relatedArticle',
type: 'reference',
to: [{type: 'article'}],
}),
],
})For the full list of configuration options, see the plugin README on GitHub.
Migrating from v4 to v5/v6
Version 5 of the internationalized array plugin introduced a breaking change: the language identifier moved from the _key field to a dedicated language field. The _key field now holds a random, stable key for array operations. This change fixes issues with copy/paste, reordering, and Portable Text fields.
What changed
In v4, the language was stored in the array item key:
// v4 format
{
"_key": "en",
"value": "Hello world"
}In v5, the language has its own field:
// v5 format
{
"_key": "a1b2c3d4",
"language": "en",
"value": "Hello world"
}Update your GROQ queries
After migrating, update any GROQ queries that filter by _key to use the language field instead:
// Before (v4)
*[_type == "product"]{ title[_key == "en"][0].value }
// After (v5)
*[_type == "product"]{ title[language == "en"][0].value }For detailed migration steps and a data migration script, see the migration guide in the plugin README.