Datasets
Managing multiple datasets within a project
A dataset is a collection of JSON documents that can be of different types and have references to each other. You can think of a dataset as a “database” where all of your content is stored, whereas the document‘s types would constitute “tables”. Using GROQ or GraphQL you can always query and join data across documents within a dataset, but not across them. Typical applications of datasets are:
- Operate with different environments for testing, staging, and production.
- Localization and segmentation across all content types.
- Different purpose content, but with same user access and billing.
https://<projectId>.api.sanity.io/v2021-06-07/data/query/<dataset>?query=*
You can also specify which dataset to use with the client libraries (configured when initializing a client) and Sanity Studio (configured in sanity.config.ts or using environment variables).
Dataset management
Datasets can be created and managed using the sanity command-line tool by running sanity dataset create <name> or sanity dataset list. To see all dataset-related subcommands, run sanity dataset.
Datasets can also be created and deleted in the project's management console, under the "Datasets" tab.
A dataset name must be between 1 and 64 characters long. It may only contain lowercase characters (a-z), numbers (0-9), hyphens (-), and underscores (_), and must begin and end with a lowercase letter or number.
Private datasets
This is a paid feature
This feature is available in the Growth plan.
Private datasets allow you to create authenticated-only access to your data. Unlike public datasets, which anyone can query, private datasets will require a valid personal or robot token with access in order to read any data.
It’s common to use private datasets behind another layer of authentication specific to your organization, then use an authenticated token to present the data. You can also use private datasets in conjunction with the App SDK to build internal dashboards that Sanity-authenticated users can access.
Datasets revert to public when trials end
For users on a trial account, private datasets revert to public if the trial ends. To avoid unexpected data access, upgrade to a full plan that supports private datasets.
Unauthenticated requests to private datasets
Unauthenticated requests to a private dataset return an HTTP 200 with an empty response in the requested shape, not a 401. For example, a query for a list returns an empty array.
When a query against a private dataset returns no results, check that your request is sending a valid bearer token before assuming the data is missing.
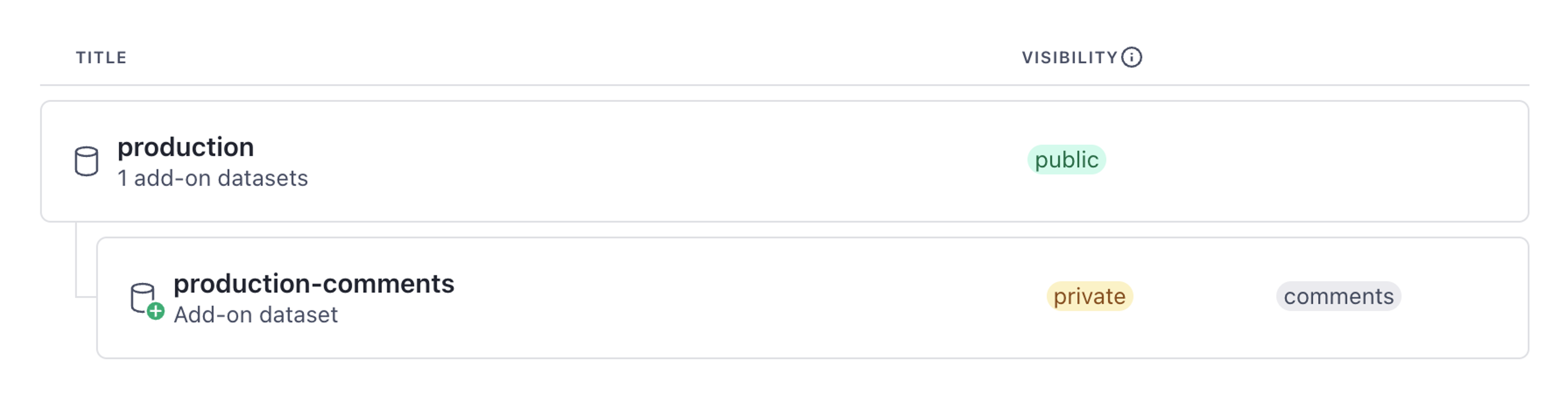
Add-on datasets
Some features automatically create "add-on" datasets and pair them to your dataset. These are complimentary and don't count toward your plan's dataset limit.
You can manage these as you would any other dataset. Learn more about configuring comments and tasks, which both create complimentary add-on datasets.
Dataset migration
You can export and import content to datasets, as well as performing mutations and patches to documents in them.
Dataset exports are billed against your API quota. Documents are streamed to minimize quota usage, but using cursor mode for large datasets will use more requests than stream mode.
Advanced dataset management
This is a paid feature
This feature is available on certain Enterprise plans. Talk to sales to learn more.
You can initiate dataset copying directly in the cloud and create aliases to hot swap between datasets without changing the underlying code for your project.