Cross-dataset references
All you need to know about creating references across datasets.
This is a paid feature
This feature is available on certain Enterprise plans. Talk to sales to learn more.
A fundamental requirement for enabling a content-driven workflow is having access to the proper tools to help you compartmentalize and then connect your content. A way of composing sets of fields to create documents, and of connecting documents to create relationships. Boxes and arrows, if you will.
The premier tool for connecting content in Sanity is the reference schema type, for creating binding relationships between content types. The reference type only allows references within a single dataset. This covers most use cases, but sometimes more complex architectures and content needs present a legitimate case for a way of communicating across datasets.
Enterprise organizations often have different teams working with different content across channels, geographies, and markets. You might have one team managing product data. A handful of other teams each in charge of the digital experience for their specific brand, in their specific market. And a centralized legal team, who supports various brands and markets by providing copy for Terms of Service, warranties, and other official information. Making sure these teams all refer to the same single source of truth for any specific bit of content is a challenge in most CMSes and often leads to duplication of effort and content debt.
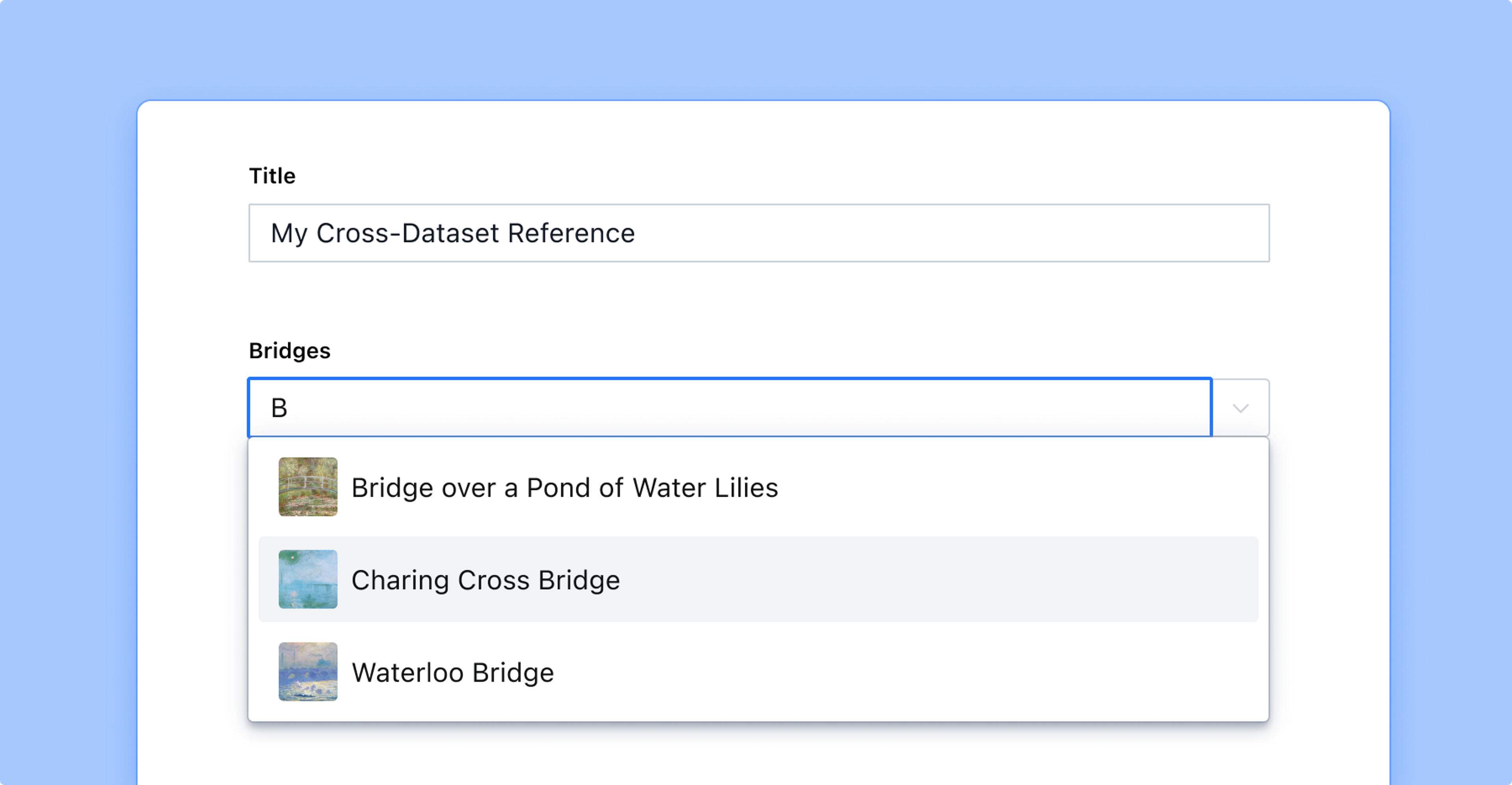
For these scenarios, there is the crossDatasetReference schema type! With it comes the ability to make references between documents in different datasets. See the CrossDatasetReferenceDefinition reference for the full type definition.
While closely related to the reference type, the crossDatasetReference type has some unique capabilities and some different limitations that you should be aware of.
The anatomy of a cross-dataset reference
A cross-dataset reference is, as its name suggests, a reference in one dataset to a document in another dataset. In order for this to be possible, there are some requirements that must be met.
For the remainder of this article, we’ll use the term referencing dataset when we discuss the dataset where the reference originates (i.e., the document that has a field pointing to a document in a different dataset), and referenced dataset when we talk about the dataset that is being referred to.
- Both datasets must belong to the same project, which must be on an enterprise plan and have this feature enabled.
- Cross-dataset references are supported in all current versions of Sanity Studio (legacy Studio v2 requires
v2.34.3or later). - The dataset name of the referenced dataset must be known at the time of creating the reference field in the referencing dataset.
- Similarly, the type of document you wish to refer to in the referenced dataset, and one or more of its fields, must be known in order to set up previews in the referencing dataset.
Exploring the crossDatasetReference schema
To read details about the crossDatasetReference schema type, visit the schema type reference documentation.
The crossDatasetReference type is, as mentioned, closely related to the reference type. It supports most of the same properties and options, in addition to some specific ones. Let’s have a look at a minimal example of a crossDatasetReference schema, and then go a bit further once we’ve established the basics.
//Type definition on the schema of the "referencing" dataset,
//i.e. where the reference originates
{
name: 'my-reference-field',
title: 'Reference to a document in another dataset',
type: 'crossDatasetReference',
dataset: 'name-of-the-other-dataset',
to: [
{
type: 'article',
preview: {
select: {
title: 'title'
},
},
},
],
}- All fields in the above example, except the title, are required.
- The
typemust be set tocrossDatasetReference. - The
datasetmust have the appropriate value. - The
tofield accepts an array of entries to different document types in the referenced dataset. You may define as many types here as you please, but eachcrossDatasetReferencefield is limited to connecting to a single referenced dataset. - Because the entire schema of all document types in the referenced dataset is not known to the referencing dataset, the following is true for each entry in the
toarray:- In addition to
type, each entry must specify one or more fields to use when searching for and previewing content in the referenced dataset. To learn more, refer to the previews and list views documentation.
- In addition to
Let’s add a few more fields and a little more complexity to our schema:
{
title: 'Reference to a document in a another dataset',
name: 'myCoolReferenceAcrossDatasets',
type: 'crossDatasetReference',
dataset: 'name-of-other-dataset',
studioUrl: ({ type, id }) => `https://target.studio/structure/${type};${id}`,
to: [
{
type: 'article',
preview: {
select: {
title: 'title',
media: 'heroImage',
},
},
},
{
type: 'person',
preview: {
select: {
name: 'name',
picture: 'portrait',
honorific: 'jobTitle',
},
prepare({ name, picture, honorific }) {
return {
title: name,
media: picture,
subtitle: honorific,
};
},
},
},
],
}Let’s look at what we’ve added.
- The
studioUrlfield on line 6 accepts a function, which is invoked with thetypeandidof your referenced document, and which should return a string in the shape of a URL to the document editing pane address in the referenced dataset studio. This field is used to create a direct link from the reference preview to its editing environment (providing your editors have access to it, of course). - Finally, we’ve added a second document type to our
toarray with an expanded preview configuration.
The cross-dataset reference field in your Studio
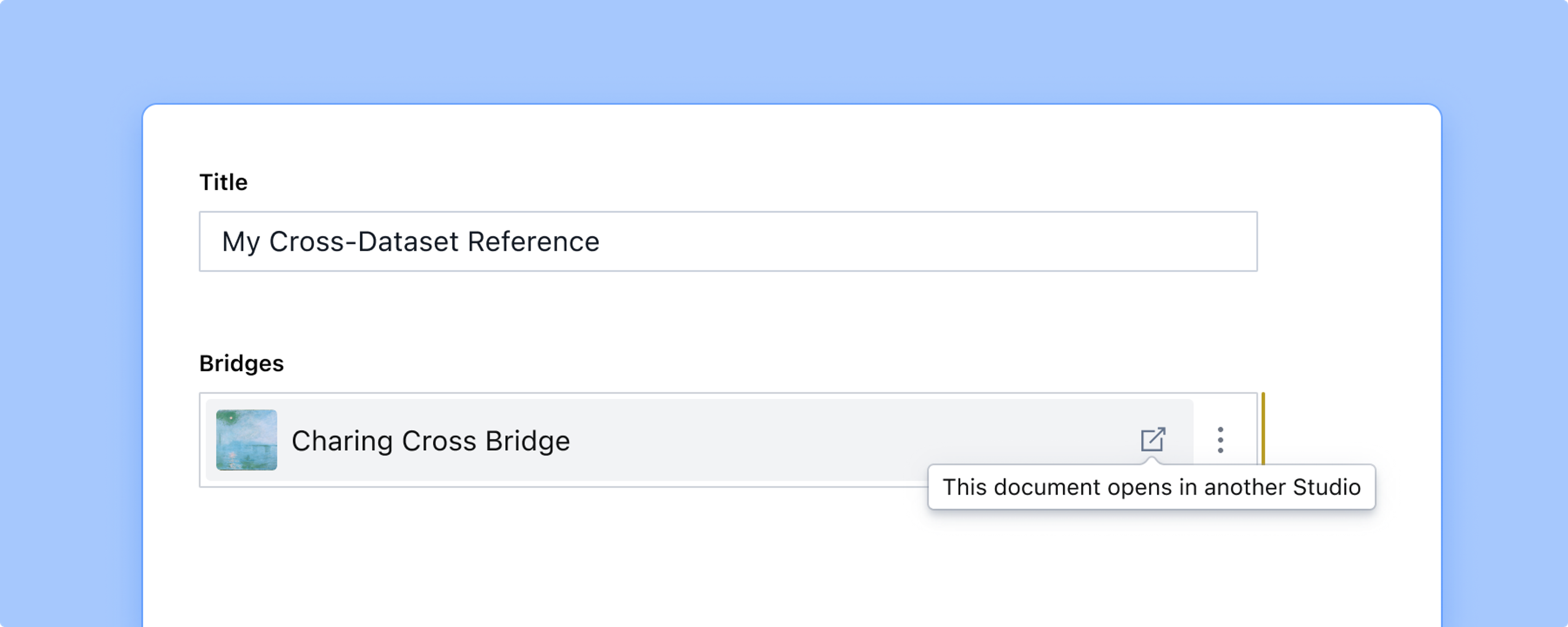
Having configured your schema, you should see the crossDatasetReference field show up in your Studio. While similar to reference inputs, they differ in some key aspects:
- The “Create New” button and option to open the referenced document in a new pane to the right are not available across datasets. Instead, you will find an intent link that will open the referenced document in the target studio (if you have access to it, and have set the
studioUrlproperty). - Linking to drafts is not available across datasets. Unless the document has been published at some point, it will not show up in search.
- Depending on network conditions, searching and previewing cross-dataset reference fields might be less performant than doing the same operations on internal references.
Editor support for cross-dataset references
Protip
The visibility of cross-dataset references depends on the permissions of the current user or token. For private datasets this means that:
- A user or token can see that a reference exists if they have at least read permissions on the source document. If they don’t have read permissions on the target document, they’ll see that the reference exists but not the content of the target document.
- A user or token can fetch the referenced document if they have at least read permissions on the target document.
- A user who wants to create a reference to a document can search for and attach any documents they have read permissions on.
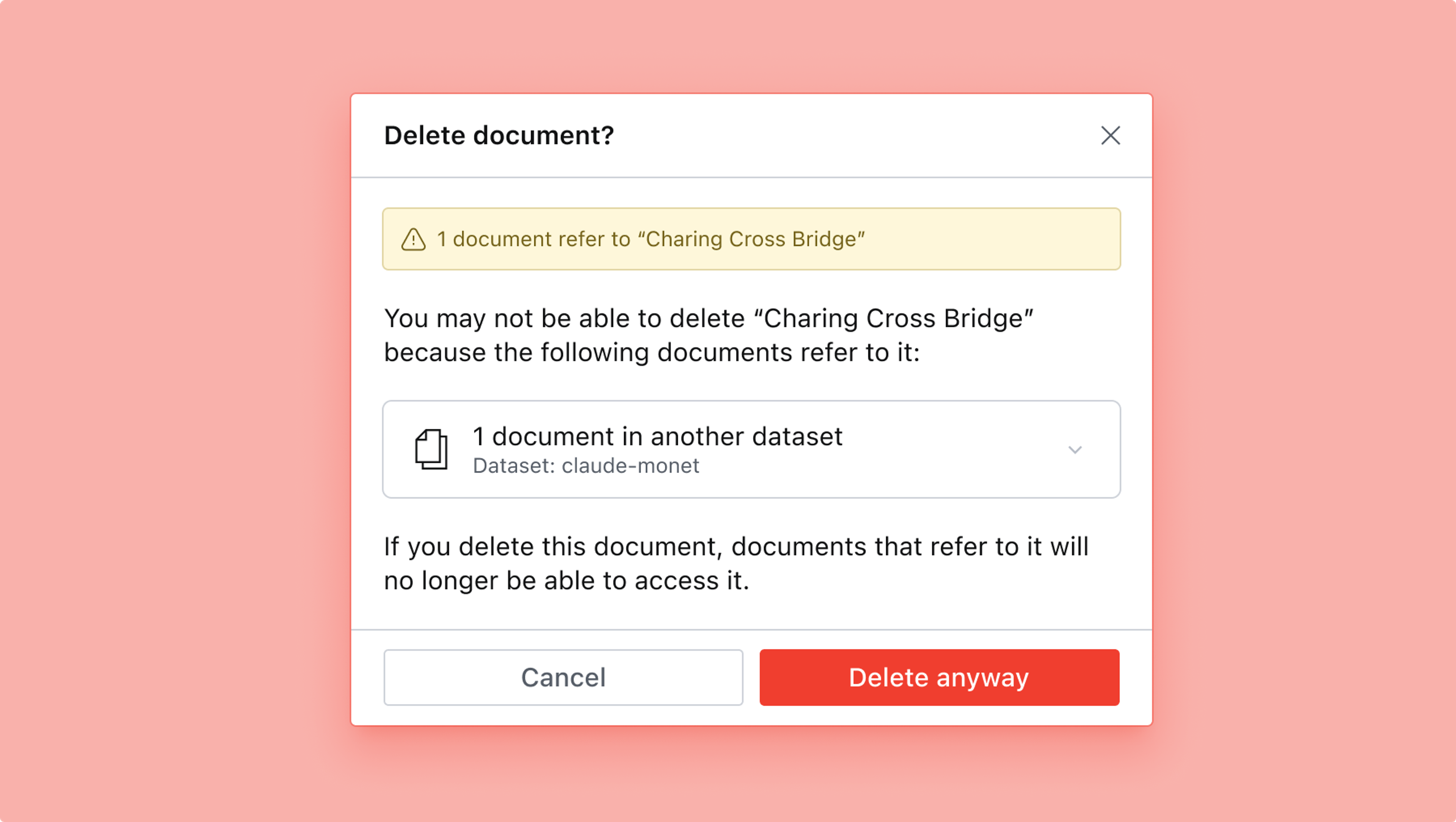
As with the reference schema type, crossDatasetReference fields are by default assumed to have bidirectional integrity, which means that if you try to delete a document that is referred to by another document, the Studio will alert you with a warning.
However, unlike references within a single dataset, the studio will allow you to proceed with deleting or unpublishing documents that are referenced by cross-dataset references from other datasets.
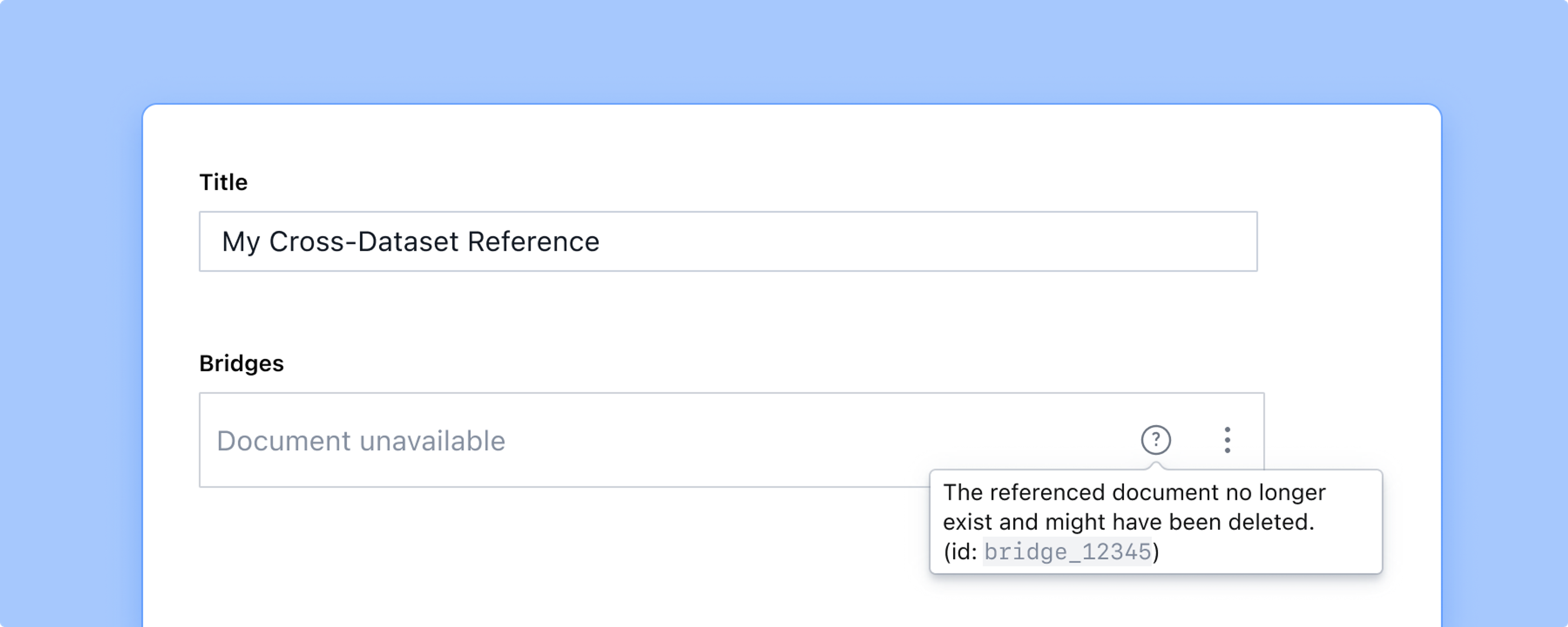
If you go ahead and delete the document despite the warnings, it will show up as unavailable in any studio referencing it and will block publishing until the problem is fixed if any changes are made to the referring document.
These measures are in place so that you can feel confident about connecting your content across datasets, and that you will be notified if a referenced document disappears.
Sometimes you don't need this guarantee but want to keep the convenience of references. This warning can be turned off by adding the weak: true property to a reference field configuration.
You will still be notified that the document you are referring to has gone missing, but you will no longer be blocked from publishing.
Querying cross-dataset references
Gotcha
Cross-dataset references require you to use API version v2022-03-07 or later. Read more about the Sanity API versioning scheme here.
Gotcha
Cross-dataset references can only be dereferenced using GROQ queries. Dereferencing through GraphQL endpoints is not currently supported.
To GROQ, a crossDatasetReference behaves similarly to an internal reference, except that dereferencing must always start from the “referencing” document. For example, for these two schemas, each in a different dataset:
// Movie type (movies-dataset)
{
name: 'movieName',
...
},
{
name: 'Actors',
title: 'Actors',
type: 'array',
of: [{
type: 'crossDatasetReference',
dataset: 'people-dataset',
to: [
{
type: 'person',
preview: {
select: {
name: 'firstname'
},
},
},
]
}]
}// Person type (people-dataset)
{
name: 'firstname',
...
},
{
name: 'lastname',
...
},
...A GROQ query starting at the movie type can dereference the “actors” field elements to retrieve the person document's fields:
*[_type == "movie"] {
...,
"actors": actors[]->{
...,
firstname,
lastname,
}
}There are no limitations on the number of levels or nesting of references supported by the dereferencing operation, but dereferencing can only be done through the -> operator, following the “unidirectionality” of cross-dataset references. For example, if the person type had an “awards” cross-dataset reference field, it could be further dereferenced as follows:
*[_type == "movie"] {
...,
"actors": actors[]->{
...,
firstname,
lastname,
awards->name
}
}However, other ways of dereferencing, for example, using the references() function, are not supported:
// This is a NOT SUPPORTED query
*[_type == "movie"] {
...,
"actors": actors[]->{
...,
firstname,
lastname,
"awards": *[_type == "awards" && references(^._id)] // <== here the reference function will not work for a cross-dataset reference
}
}Perspectives are limited to the initiating dataset (API versions prior to 2025-06-19)
Prior to API version 2025-06-19, Perspectives only applied to the initiating dataset and would not apply to items in the referenced dataset. This can result in only seeing published documents, even when in preview environments.
As of v2025-06-19, cross-dataset references now respect the perspective of the querying dataset.
In conclusion
The cross-dataset reference schema type is a powerful tool for enabling shared content across datasets. It allows you to keep your content connected beyond its original context by extending the reference field with methods for authenticating and querying across datasets.
Further reading: