High-performance GROQ
GROQ gives you a fast, expressive way to query data from Sanity.
Occasionally you may discover that queries that were initially fast when the dataset was small have become slower as the dataset has grown and the queries have become more complex and resource-heavy during development.
Unlocking optimization in the way you write queries can be helped by understanding the way in which a query is executed. In this document we'll explain how the query engine works, and how to avoid certain pitfalls that can make your queries slow.
Understanding fetching, filtering, and sorting
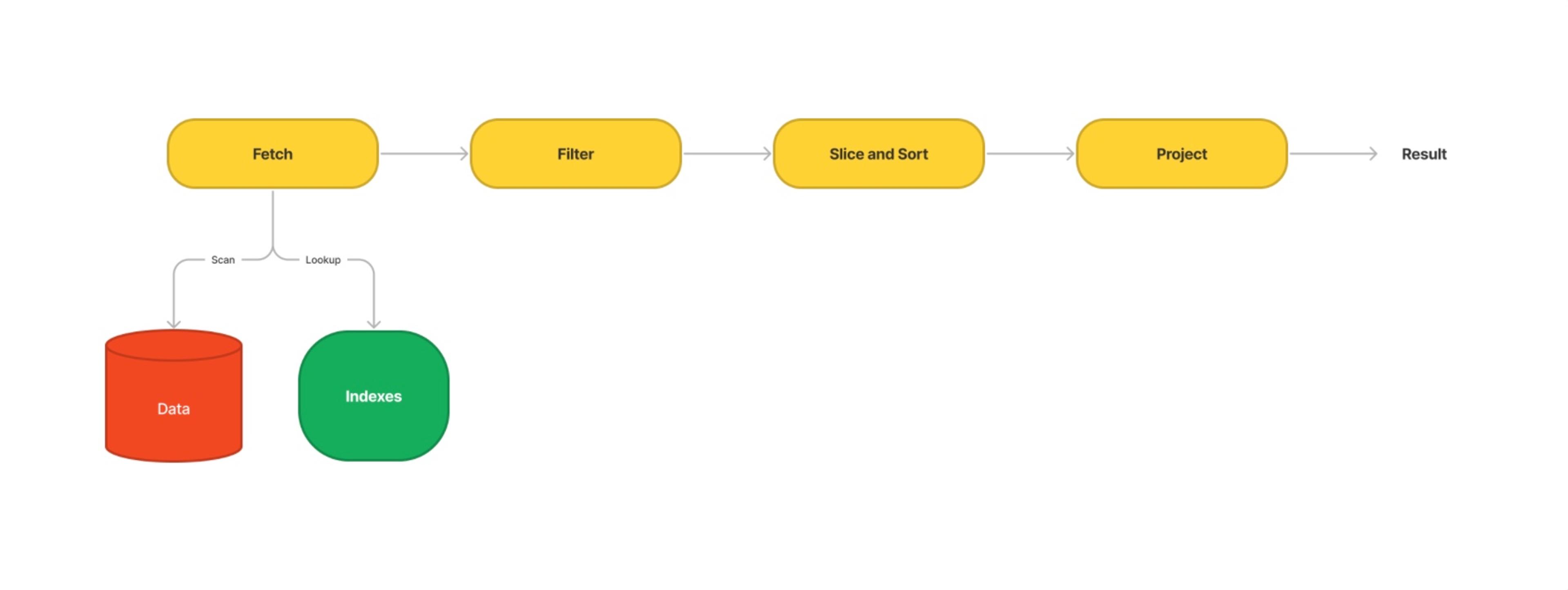
The GROQ query engine is designed to deconstruct a query into a set of pipelines according to a query plan. A pipeline has the following broad structure:
Most GROQ queries start by fetching data. The shortest query you can write looks like this, and will return all documents:
// Fetch all documents *[]
Anything we write inside of a pair of square brackets will filter the results. Let’s update our query to filter for just product type documents:
// Only fetch documents where the '_type' field equals 'product' *[_type == "product"]
This filter is made of three parts:
_typeis an identifier, referring to the attribute of a document==is an operator, “equals”"product"is a literal, in this instance a string
This query is fast because we know ahead of time what we want _type to equal. So the query can perform a filtered fetch against the dataset’s indexes for exact matches. Internally, the query engine uses special index structures to optimize such queries, which may be familiar to you from traditional SQL databases.
Queries that can do filtered fetches are the fast type of query. But it’s also possible to write a query that is unable to do filtering efficiently, which will often make the query execute slowly.
Gotcha
Inefficient filtering may not become apparent until your dataset reaches a certain size. Small datasets are inherently fast to query. A query that executes against a dataset of five documents may take a millisecond. But once your dataset grows to thousands of documents, performance issues may start to crop up.
Similarly to filtering, using sorting in a query can be unexpectedly slow. The order() function is designed to also make use of index structures, which means it generally only accepts simple attributes or attribute paths. For example, the following query cannot be optimized and must load the entire result set into memory to sort it:
// This cannot be optimized, because the order expression uses string concatenation
*[_type == "person"] {
firstName, lastName
} | order(firstName + " " + lastName)Unfiltered over-fetches
It’s possible to write filters that cannot be optimized to make use of our internal index structures. One example is when they use a non-literal expression on both sides of the operator.
Imagine our product documents have both salePrice and displayPrice number fields. Since the Content Lake is schemaless and we know these fields only exist on product documents, let’s fetch all products that are currently discounted with the shortest possible query.
// Fetch all documents // ...then filter down to those where salePrice is less than displayPrice *[salePrice < displayPrice]
salePriceis an identifier, assumed to be a numeric attribute that exists<is an operator, “less than”displayPriceis an identifier, assumed to be a numeric attribute that exists
This is not something that the query engine can optimize, because neither salePrice nor displayPrice are known ahead of time. In order to satisfy the filter expression, we explicitly need to look at every single document.
So in this case, the GROQ query engine must over-fetch for all documents, loading every single document into memory and then filtering the results by the expression.
Protip
See reference below. For a list of optimizable filter expressions, see the reference section at the end of this document.
The parent operator
The parent operator ^ is a notable exception to the rule above. Consider a document that contains a reference to a parent document. An additional subquery will fetch all documents that also have the same parent reference:
// Direct-use of the parent operator is optimized
*[_type == "person"] {
_id, parent,
"siblings": *[_type == ^._type && parent._ref == ^._id]
}Note: This is currently only optimized where the expression satisfies the expressions listed in the Reference: Filter expressions section at the end of this document. Using an expression on ^ together with a function, string concatenation, etc. may not be optimized. For example:
// String concatenation of the operator is not optimized
* { _id, "draft": *[_id == "drafts." + ^._id] }Counting aggregation
Similarly to filtering, a count() is only optimizable if its interior expression is completely optimizable. For example:
count(*[_type == "person" && isPublished])
This, on the other hand, is not optimizable:
// Not optimizable, because it uses == with a computed expression count(*[_type == "person" && (firstName + " " + lastName) == "Ronald McDonald"])
Sorting
As with filtering, sorting is only optimizable on certain types of expressions such as single attributes:
* | order(name)
Deep array indexing and slicing
It's worth talking about what happens when you slice a query result:
// Deep index *[_type == "article"][10000] // Deep slice *[_type == "article"][10000..10100]
All results returned by * always have a sort order; even if you don't specify an order(), the results will be ordered by _id. This means that to slice a subset of the results, the entire dataset needs to be sorted and the first 10,000 results "skipped" over in order to reach the slice range.
While this sorting and skipping is quite fast, the performance is directly related to the number of results that are skipped. For example, if getting [1000] takes 100ms, you can expect [2000] to take about 200ms.
Query performance and dataset size
Dataset growth should have no impact on optimized, filtered queries that return the same amount of data. For example, this query should return at the same speed whether there are 100 or 100,000 documents in the dataset.
*[slug.current == "discounted"]._id
Tips and tricks
Reduce search space by “stacking” filters
If your query cannot be written to avoid this comparison of non-literals, you can stack additional filters into your query to reduce the number of documents loaded into memory before filtering.
For example, we can be explicit about the _type and in this hypothetical we know that not all products even have a salePrice field.
// Only fetch documents where: // the '_type' field equals 'product' and it has a 'salePrice' field // ...then filter down to those where salePrice is less than displayPrice *[_type == "product" && salePrice != null && salePrice < displayPrice]
This query can now run faster because it only needs to look at products where the salePrice exists as an attribute. But it's best to avoid comparisons of non-literals where possible.
Avoid repeated resolving of references
GROQ resolves references with the reference access operator ->. The simplicity of this syntax hides its functionality, however. This -> operator is actually a subquery in disguise:
// Fetch all categories titles and parents:
*[_type == "category"] {
title,
parent->
}
// ...is the same as:
*[_type == "category"] {
title,
"parent": *[_id == ^.parent._ref][0]
}This is fine in the above instance where we are resolving the reference once. However, needlessly repeating the -> operator will perform that subquery over and over.
// Slow, repeated subquery
*[_type == "category"] {
title,
"slug": slug.current,
"parentTitle": parent->title,
"parentSlug": parent->slug.current
}We can instead use the expansion operator, ...:
// Merge a single subquery into the root level of the result
*[_type == "category"] {
title,
"slug": slug.current,
...(parent-> {
"parentTitle": title,
"parentSlug": slug.current
})
}Reduce the amount of data returned
The expansion operator ... is a convenient way to return all data. However, this may be returning significantly more data than required. This can impact the speed at which your data is returned.
For example, our query for discounted products is currently returning every field in each document. But we could scope this down to required parts once our frontend knows exactly what it needs.
// Return all fields and resolve all fields in all 'categories' references
*[_type == "product" && defined(salePrice) && salePrice < displayPrice]{
...,
categories[]->
}
// Return just these required fields and the title of each 'categories' reference
*[_type == "product" && defined(salePrice) && salePrice < displayPrice]{
title,
salePrice,
displayPrice,
"categories": categories[]->title
}Avoid joins in filters
The -> operator can be used to pull in related data. However, it is a comparatively expensive operation, and should be used with care.
It is particularly expensive to use -> inside a filter expression:
*[_type == "post" && author->name == "Bob Woodward"]
Avoiding this can be difficult, but spending a little more time on the data modeling can be worth the effort. While “denormalizing” a data model is often considered a negative, a little denormalizing for frequently used “core” fields can significantly improve query performance.
Another common pitfall is using a related document’s field as an “identity” field, rather than relying on that document’s ID. This is a sign of poor data modeling:
*[_type == "post" && vertical->slug.current == "football"]
Instead, consider using the ID itself:
*[_type == "post" && vertical._ref == "football-doc-id"]
Avoid resolving assets
It may be tempting to resolve an asset reference in order to get its URL. This URL is to the full-size image and therefore not optimized. The rest of the metadata on the asset record may not be used by your frontend and adds bloat to the amount of data returned.
*[_type == "product"]{
// Resolves much more metadata than you probably need
image->,
// The URL of a full-size, unoptimized image
"imageUrl": image->asset.url,
// Just get the image _ref and dynamically create the URL
image
}However, the _id assigned to an image once uploaded is deterministic, unique to that specific file, and contains a lot of data about the image itself like its filetype and size.
So you can dynamically create a URL using just the projectId, dataset, and _id of the image.
Avoid reusing projected values
A common mistake is to use a projection expression, followed by additional query expressions that filter or sort. For example:
// Sorting on a projected attribute
*[_type == "person"] {
"name": firstName + " " + lastName,
"isBoss": role->name == "boss",
} | order(isBoss, name)
// Filtering on a projected attribute
*[_type == "person"] {
"isBoss": role->name == "boss",
}[isBoss == true]In these two queries, the expressions we use (order(isBoss, name) and isBoss == true) look like they satisfy the constraints we explained earlier; after all, they are using simple attributes. But they are in fact not optimizable, since the attributes in question are computed at query time.
Protip
The query engine is smart enough to know if an attribute is merely being renamed or moved around. For example, *{ "foo": bar.baz } | order(foo). Here, even though foo is a “made up” attribute, the query engine understands that it can sort on bar.baz.
Avoid large queries
The bigger a GROQ query, the longer the engine takes to parse and plan it. It can also be slow for a web browser to send several hundred kilobytes of GROQ to the backend.
Avoid slicing when "paginating"
It's tempting to use slicing to fetch results in pages:
*[_type == "article"] | order(_id)[1000..1020]
As described above, this is inefficient. You can make this faster by paginating by a field instead:
*[_type == "article" && _id > $lastId] | order(_id)[0..20]
For each page, you can note down the highest _id and use that as the next $lastId.
Parallelize independent queries
A common technique for “page builder”-driven applications is to build a “superquery” that collects data for multiple components at once:
{
"topPosts": *[_type == "post" && category == $category]
| order(popularity desc)[0..30],
"news": *[_type == "news"] | order(_createdAt desc)[0..10],
"user": *[_type == "user" && _id == $id],
}This could be broken up into three queries, which allows them to be parallelized. The topPosts, news, and user queries would each be fetched separately, as in the following example using the JavaScript client:
const topPostsParams = {
category: // ...
}
const userParams = {
id: // ...
}
const topPosts = client.fetch(`*[_type == "post" && category == $category] | order(popularity desc)[0..30]`, topPostsParams)
const news = client.fetch(`*[_type == "news"] | order(_createdAt desc)[0..10]`)
const user = client.fetch(`*[_type == "user" && _id == $id]`, userParams)Explain mode
If you want to look at how your query is executed by the query engine, you can ask the API for a query plan. You do this by providing the explain parameter, which you can read more about in the API reference.
The explain format
The format used for the explain output is currently undocumented and can be difficult to understand if you are not familiar with the query engine.
Reference: Filter expressions
The following filter expressions can always be optimized. This is not an exhaustive list.
Attributes
In the examples below, attribute can also be a dotted path such as foo.bar.baz, but not more complex attribute expressions such as foo[0].bar or foo[1..2].
Binary
Expression
Where op is one of ==, !=, <, <=, >, >=:
<attribute> <op> <literal>-
<literal> <op> <attribute>
Examples
category == "sport"age > 20
Boolean attribute
Expression
attribute
Examples
isPublished
Logical expressions
Expression
!optimizableExpression<optimizableExpression> && <optimizableExpression><optimizableExpression> || <optimizableExpression>
Examples
published && !visible!hidden || category == "post"
Arrays
Expression
<literal> in <attribute><literal> in <arrayAttribute>
Examples
"sport" in categories"user-123" in users[]._ref
dateTime() function
Expression
Where op is one of ==, !=, <, <=, >, >=:
dateTime(<attribute>) <op> dateTime(<string>)dateTime(<string>) <op> dateTime(<attribute>)
Note that now() is a special case; it evaluates to a static string at query time, and can be used here.
Examples
dateTime(publishedAt) <= dateTime(now())
defined() function
Expression
Note: This is shorthand for <attribute> != null.
defined(<attribute>)
Examples
defined(publishedAt)
string::lower() function
Note: This also applies to lower() (with no namespace).
Expression
string::lower(<attribute>) == <string><string> == string::lower(<attribute>)
Examples
lower(tag) == "football"
match operator
Expression
<attribute> match <string><attribute> match <array>
Examples
title match "content*"title match ["structured", "content"]
pt::text() function
Expression
pt::text(<attribute>) match <string>pt::text(<attribute>) match <array>
Examples
pt::text(content) match "structured content"
path() function
Expression
Gotcha
This is only optimized for the _id attribute.
_id in path(<string>)
Examples
_id in path("a.b.**")
references() function
Expression
references(<string>[, ...])
Examples
references(^._id)
Geographic functions
Expression
geo::intersects(<attribute>, <geo>)geo::contains(<attribute>, <geo>)geo::disjoint(<attribute>, <geo>)geo::contained(<attribute>, <geo>)
Reference: Sort expressions
The following expressions are optimized for sorting.
Plain attribute
Expression
order(<attribute>)
Examples
* | order(lastName, firstName)
string::lower() function
Note: This also applies to lower() (with no namespace).
Expression
order(string::lower(<attribute>))
Examples
* | order(string::lower(name))
dateTime() function
Expression
order(dateTime(<attribute>))
Examples
* | order(dateTime(publishedAt))