Perspectives for Content Lake
Perform the same query but with different results based on the published or draft status of a document.
Note on data privacy, drafts, and authentication
Sanity offers a range of tools for granularly managing access to your content. The rest of this article presumes that all requests are made from an authenticated client with permissions to see both drafts and published content.
You can learn more about data security, the drafts model, or how Sanity limits access to content in public datasets using IDs and paths at the following destinations.
The Perspectives feature allows you to query your datasets from a different viewpoint with minimal configuration. You can use the drafts perspective to treat all drafts as published, a perspective stack of release IDs to view a custom perspective with Content Releases, or the published perspective to exclude all unpublished changes from your results. The raw perspective will returns all drafts, versions, and published content side by side for authenticated requests.
// Example JS/TS client configuration
import {createClient} from '@sanity/client'
const client = createClient({
...config,
perspective: 'published', // 'raw' | 'drafts' | 'published' | ['release-id1', 'release-id2']
})Gotcha
With the release of API version 2025-02-19, the default perspective changed from raw to published.
Look at your content from a different point of view
Core to the idea of composable, structured content is the ability to weave content from any number of independent but interconnected documents into whatever shape is required on the consuming end. Sanity’s Content Lake lets you write queries that can filter, combine, merge, expand references, and apply transformations to the original content in your dataset.
This flexibility also means that often your query results will be made up of bits and pieces from a multitude of source documents and that sometimes previewing what your app, website, or experience will look like after you hit that publish button can become complicated and cumbersome. Previewing content changes before committing to production in an environment that is as realistic as possible is vital to a smooth editorial experience.
Using the drafts and published perspectives
Perspectives allows your GROQ queries to run against an alternate view of the content in your dataset – very similar to how “views” work in traditional databases. The perspective is set as an additional parameter in the client config or API call so that your queries can remain identical between different implementations, such as a preview and production deployment. In addition to the default perspective, which can be explicitly set by using perspective: 'raw', two new built-in perspectives are initially available:
- The
draftsperspective, in which queries return your content “as if” all draft documents (i.e., unpublished changes in Studio) were published - The
publishedperspective, in which queries return your content “as if” no in-flight unpublished changes existed
Protip
The drafts perspective used to be called previewDrafts. They both work, but if you're using the latest APIs you should transition to drafts. You may see both mentioned throughout the documentation.
Requesting either of these alternative perspectives is a matter of adding one line to your client configuration or passing a URL parameter if you’re using the HTTP API.
// Example JS/TS client configuration
import {createClient} from '@sanity/client'
const client = createClient({
...config,
useCdn: false, // must be false when using 'drafts'
perspective: 'drafts', // 'raw' | 'drafts' | 'published'
})// Example using HTTP API /data/query/production?query=*[]&perspective=drafts
Gotcha
Queries using the drafts perspective are not cached in the CDN, and will return an error if useCdn is not set to false. You should always explicitly set useCdn to false when using drafts!
Example output from different perspectives
Let’s look at a very minimal example dataset with different perspectives applied.
raw
import {createClient} from '@sanity/client'
const client = createClient({
...config,
perspective: 'raw', // default value, optional
})
const authors = await client.fetch('*[_type == "author"]')Making our initial query with the default raw perspective (explicitly set in this example but can safely be omitted) reveals that we are looking at a dataset of authors that contains the following documents:
- a published document (Ursula Le Guin)
- with unpublished changes in a corresponding draft document (Ursula K. Le Guin)
- a draft document that has never been published (Stephen King)
- a published document with no pending changes (Terry Pratchett)
[
{
"_type": "author",
"_id": "ecfef291-60f0-4609-bbfc-263d11a48c43",
"name": "Ursula Le Guin"
},
{
"_type": "author",
"_id": "drafts.ecfef291-60f0-4609-bbfc-263d11a48c43",
"name": "Ursula K. Le Guin"
},
{
"_type": "author",
"_id": "drafts.f4898efe-92c4-4dc0-9c8c-f7480aef17e2",
"name": "Stephen King"
},
{
"_type": "author",
"_id": "6b3792d2-a9e8-4c79-9982-c7e89f2d1e75",
"name": "Terry Pratchett"
}
]published
import {createClient} from '@sanity/client'
const client = createClient({
...config,
perspective: 'published',
})
const authors = await client.fetch('*[_type == "author"]')Running the same query with the published perspective specified yields a result where all drafted changes and unpublished documents have been excluded. This perspective is useful for ensuring that unpublished content never ends up in a production deployment.
[
{
"_type": "author",
"_id": "ecfef291-60f0-4609-bbfc-263d11a48c43",
"name": "Ursula Le Guin"
},
{
"_type": "author",
"_id": "6b3792d2-a9e8-4c79-9982-c7e89f2d1e75",
"name": "Terry Pratchett"
}
]drafts
import {createClient} from '@sanity/client'
const client = createClient({
...config,
useCdn: false, // must be false, required for this perspective
perspective: 'drafts',
})
const authors = await client.fetch('*[_type == "author"]')Viewed through the drafts perspective, our content is returned with all drafts applied. Documents are deduped in favor of the draft version, and unpublished draft documents are returned as if published. Note also that each document now has an _originalId property which identifies its origin.
[
{
"_type": "author",
"_id": "ecfef291-60f0-4609-bbfc-263d11a48c43",
"_originalId": "drafts.ecfef291-60f0-4609-bbfc-263d11a48c43",
"name": "Ursula K. Le Guin"
},
{
"_type": "author",
"_id": "f4898efe-92c4-4dc0-9c8c-f7480aef17e2",
"_originalId": "drafts.f4898efe-92c4-4dc0-9c8c-f7480aef17e2",
"name": "Stephen King"
},
{
"_type": "author",
"_id": "6b3792d2-a9e8-4c79-9982-c7e89f2d1e75",
"_originalId": "6b3792d2-a9e8-4c79-9982-c7e89f2d1e75",
"name": "Terry Pratchett"
}
]Perspective layers
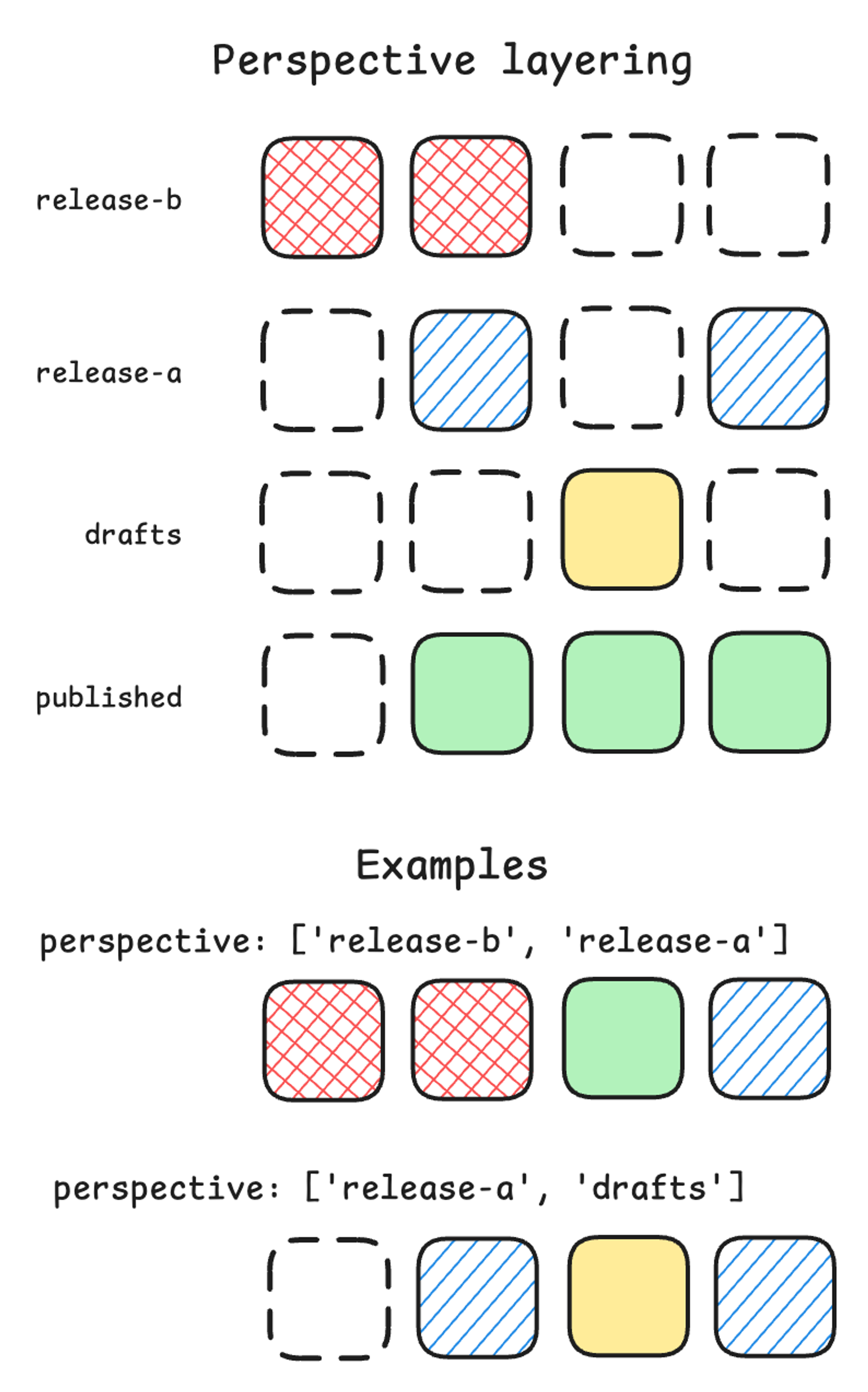
The Content Releases feature introduces the concept of the perspective laying. This allows you to create a custom perspective containing documents from multiple Content Releases, as well as published and even draft content.
To create a custom layered perspective, pass a list of release names anywhere you would normally set the perspective. For example, in the client it looks like this:
// Example JS/TS client configuration
import {createClient} from '@sanity/client'
const client = createClient({
...config,
useCdn: false, // must be false when using preview content
perspective: ['release-a', 'release-b', 'release-c'],
})Layers are prioritized from left to right. In the example above, updates in release "a" will override release "b", updates in release "b" will override release "c", and so on. The published perspective is automatically added to the end of the list.
In this diagram, you can see releases mixing with draft and published content. Note that while the published perspective is automatically added to the end of a stack, the drafts perspective is not.
For more on using perspective with releases, see the Content Releases API documentation.