Moving the Mux blog to the JAMstack
In this post, Dylan from Mux.com presents why and how they moved their blog to the JAMstack using Sanity.io for content, and Gatsby.js to build the frontend.

Dylan Jhaveri
Developer experience at Mux.com
Published
This is a post from Dylan from Mux. Mux is a company that provides APIs for video. Mux recently migrated their blog to Sanity and started using Sanity as a headless CMS for their marketing website.
A couple of months ago we finished the process of moving the Mux Blog to Sanity. Here’s a walkthrough of how we did that and the decisions that were made along the way. Some code snippets are included and a full deep dive can be found in this guide.
Before this project, the Mux blog was hosted and deployed separately from mux.com. The blog was powered by an old version of Ghost. Our marketing site (mux.com) is a Gatsby site that uses gatsby-source-filesystem to create some pages from markdown and gatsby-source-airtable to pull in some data from Airtable.
Gatsby is an open-source framework that roughly works like this:
- Pull in data from arbitrary 3rd party data-sources at build time.
- Write your pages as normal React components.
- When you deploy, Gatsby “builds” your site by precompiling all your pages so that each page serves static HTML while also preserving all the interactive functionality in your react components.
- Gatsby also automatically code-splits your pages so that each page only loads the HTML, CSS, and Javascript that is needed.
Overall, Gatsby works pretty well for our marketing site. It isn’t without it’s quirks and issues (particularly when venturing off the happy path and into the 3rd party ecosystem), but overall we’ve been really happy with it.
Our blog, however, was not on Gatsby. It was hosted separately on Ghost. The big issues we ran into were:
- Difficult to customize the look and feel: Since we were using a Ghost theme, not only was the design of the blog different from the design of the rest of our marketing website. But it was an entirely different application with a different structure, hosting and deploy process.
- One author per post: Blog posts in our old system were only allowed to have one author. In reality, some of our posts are written by multiple people on our team and we wanted to highlight that by showing multiple authors on a post.
- We want categories, not tags: We’re not a big fan of having a lot of arbitrary “tags” for a blog post. Having loosely-defined tags was a bit messy and resulted in duplicate tags with slightly different names and general confusion for authors when deciding what tags to apply to a post. We prefer a defined set of about 7 categories with each blog post falling into just one category.
After coming up with the requirements and creating a design that we felt good about, we then had to figure out the implementation details. We knew that we wanted to use some form of a headless CMS that we could pull in as a Gatsby source into the existing build process for our marketing site. At the time we were making this migration, we had about 130 blog posts that needed to be migrated to the new CMS. The migration would have to be with scripts, and we would have to make sure that our old blog posts migrate cleanly.
Choosing a Headless CMS
We ended up choosing Sanity as our headless CMS. We loved that Sanity felt like a developer product. Calling Sanity a headless CMS sells it short from what it really is. It’s more like a structured, real-time database. The CMS part is all open source and in your control for how you want things to work. The way to think about it is that Sanity provides a real-time database and some low-level primitives to define your data model. From there, you build your own CMS.
We wanted to set ourselves up with a headless CMS that could be used beyond just the blog and could also create a variety of pages on mux.com and allow us to move existing content like the video glossary.
Plus, Sanity already has a mux plugin that works great for uploading, transcoding and delivering videos with Mux.
Defining our schema
The first step for migrating the blog was to define the schema. We ended up with types for post (a blog post) and teamMember. A post could have one or more teamMembers or authors. We went with “teamMember” instead of “author” because we also wanted this same collection of records to be used for the mux team page.
// schemas/teamMember.js
import { IoMdHappy as icon } from 'react-icons/io'
export default {
name: 'teamMember',
title: 'Team Member',
type: 'document',
icon,
fields: [
{
name: 'name',
title: 'Name',
type: 'string',
},
{
name: 'slug',
title: 'Slug',
type: 'slug',
options: {
maxLength: 96,
source: 'name',
},
},
{
name: 'bio',
title: 'Bio',
type: 'string',
options: {
maxLength: 140,
},
},
{
name: 'image',
title: 'Image',
type: 'image',
options: {
hotspot: true,
},
},
{
name: 'public',
title: 'Public',
type: 'boolean',
description:
'If enabled, this will team member will show up on the /team page',
},
],
preview: {
select: {
name: 'name',
image: 'image',
public: 'public',
},
prepare({ name, role, image, public: isPublic }) {
return {
title: name,
media: image,
description: isPublic ? 'public' : 'hidden',
}
},
},
}Next, was to go through all the existing blog posts and figure out the list of features we needed to support in the body of a post. I ended up with 11 custom types (things like muxCta, youtubeEmbed, images) and a custom annotation for footnotes.
Encouraging images for posts (but not requiring)
We wanted to encourage blog authors to add cover images to blog posts. Cover images are handy for sharing on social media and for the design of the list page and the page for the individual posts. However, we didn’t want to be so strict as to require an image for every post.
We found a solution to make a “soft requirement” for images on blog posts. We added a boolean field called 'imageNotRequired`. By default images are required, but in the UI there is a switch where the blog author can override the requirement and create a post without an image. This felt like the right kind of subtle nudge to encourage images without being too restrictive.
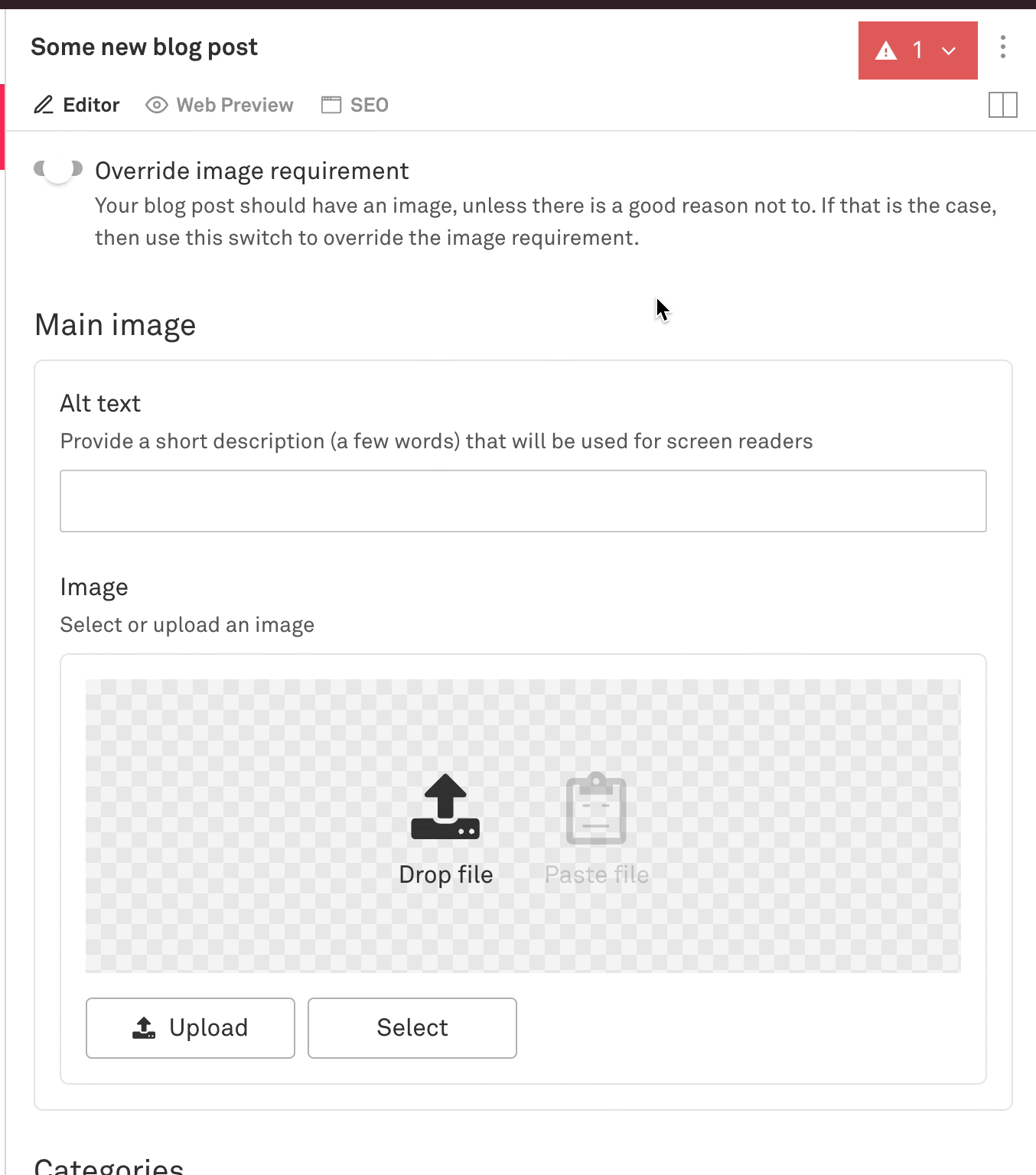
This is what the schema is for post.js and how we did that:
// schemas/post.js
import { FaRegNewspaper as icon } from 'react-icons/fa'
export default {
name: 'post',
title: 'Post',
type: 'document',
icon,
fieldsets: [{ name: 'seo', title: 'SEO meta tags' }],
fields: [
{
name: 'title',
title: 'Title',
type: 'string',
validation: Rule => Rule.required(),
},
{
name: 'slug',
title: 'Slug',
type: 'slug',
options: {
source: 'title',
maxLength: 96,
},
},
{
name: 'teamMembers',
title: 'Team Members',
type: 'array',
of: [{ type: 'reference', to: { type: 'teamMember' } }],
},
{
name: 'imageNotRequired',
title: 'Override image requirement',
description:
'Your blog post should have an image, unless there is a good reason not to. If that is the case, then use this switch to override the image requirement.',
type: 'boolean',
},
{
name: 'mainImage',
title: 'Main image',
type: 'imageWithAlt',
validation: Rule =>
Rule.custom((mainImage, { document }) => {
if (mainImage) return true
if (document.imageNotRequired) return true
return 'Add a main image'
}),
},
{
name: 'seoTitle',
title: 'Title',
description: 'This title will show in search results and social sharing',
type: 'string',
fieldset: 'seo',
validation: Rule => Rule.max(70),
},
{
name: 'seoDescription',
title: 'Description',
description:
'This description will show in search results and social sharing',
type: 'text',
fieldset: 'seo',
rows: 3,
validation: Rule => Rule.min(50).max(200),
},
{
name: 'body',
title: 'Body',
type: 'blockContent',
},
{
name: 'publishedAt',
title: 'Published at',
description:
"This field will automatically be set when you hit 'publish', but you can manually override it here if you want",
type: 'datetime',
},
],
preview: {
select: {
title: 'title',
media: 'mainImage.image',
name0: 'teamMembers.0.name',
name1: 'teamMembers.1.name',
name2: 'teamMembers.2.name',
publishedAt: 'publishedAt',
},
prepare({ title, media, name0, name1, name2, publishedAt }) {
return {
title,
media,
subtitle: `by ${[name0, name1, name2].filter(n => !!n).join(', ')}`,
}
},
},
}
Migrating old posts
After defining the schema for the blog posts and team members I checked out gatsby-source-sanity and made sure that worked in the build process for our Gatsby site. No surprises there, it worked the way I was familiar with other Gatsby sources working. The only minor issue I ran into was how to use @sanity/image-url when I don’t have access to a sanityClient instance.
Nex was the most time-intensive work — scripting the import process to bring posts from our old system into the new Sanity system. I have written about it in depth here in this guide.
Roughly the process was:
- Write an import script that processed posts from the old system and generated a
.ndjsonfile that I could use with a command like this:sanity dataset import sanity-import.ndjson production --replace - Import a batch of posts (5 or 10)
- Add or edit Sanity queries in my gatsby app
- Check the batch I imported, check if the data is structured as I expect and that the styling looks right
- Fix bugs in the import script
- Fix styling bugs
- Repeat with a new batch of posts
Our team’s new workflow
- Draft content in Google Docs. We’ve tried other tools but Google Docs still seems like the best option for sharing drafts internally and soliciting feedback from the rest of the company. More specifically, the ability to “suggest” edits and add inline comments is all seamless. No need to create another account, everyone on our team is logged into the company G Suite so this works great. We hope that one day we can compose, draft and publish all in one place, but for now we draft in Google Docs.
- After collecting feedback, the author will copy the draft from Google Docs into Sanity. This is a bit of a manual process. The basic text formatting and links copy and paste pretty cleanly, but then adding things like images, code blocks and other custom data structures is a manual process.
- Share the Gatsby Preview link internally so folks at the company can view the final draft the way it will look on production. This is an opportunity to get a final round of feedback before publishing.
- When ready, click publish! Sanity will send a webhook that builds and deploys the new production version of the marketing site.
If you want to chat more about video or Sanity you can find me on Twitter @dylanjha or check out more of our writing on the Mux blog (powered by Sanity).