Published October 03, 2022
Simplifying GROQ queries for complex “Page Builders”

Creating very flexible schema can result in very complex GROQ queries. Switching to a "waterfall" of smaller queries can make them more reliable, and potentially faster.
The flexibility of Sanity Schema and GROQ allows for freedom of expression. Left unchecked, this freedom can get you into trouble. Specifically when it comes to “Page Builders”.
In this Guide we’ll look at how changing the way we query for a single document's complex content.
You may find this Guide useful if you are currently working with:
- Huge, hard to debug GROQ strings
- Intermittent timeout errors with large queries
- “300kb Query Size Exceeded” errors with queries
A quick aside on Page Building in general
Sanity and Responsible Page Building is a topic worthy of much longer discussion.
The appeal of this pattern is understandable, content authors are free to create free-form layouts within predefined blocks.
However, when overly relied upon it becomes an anti-pattern for Structured Content. Limits reuse and buries content, making it difficult to find.
As a guide, consider the following:
Restrict use: Limit to Pages with temporary, constantly updated, short-lived or time-sensitive content. For example: Home page, campaign page, offer page.
Limit presentational options fields: It’s better to let your design system decide how a component should look, rather than present editors with a confusing myriad of options like padding, margin, font size and color.
Leverage references: Any piece of content which could have potential reuse in more than one location should be a reference, not be stored in a text field of the second column of the third block of the landing page of your latest promotion.
Consider context: Content authored in hero.title has no explicit meaning and a rigid presentation. Content authored in lesson.title has explicit meaning and its presentation is boundless.
What your Page Builder workflow looks like today
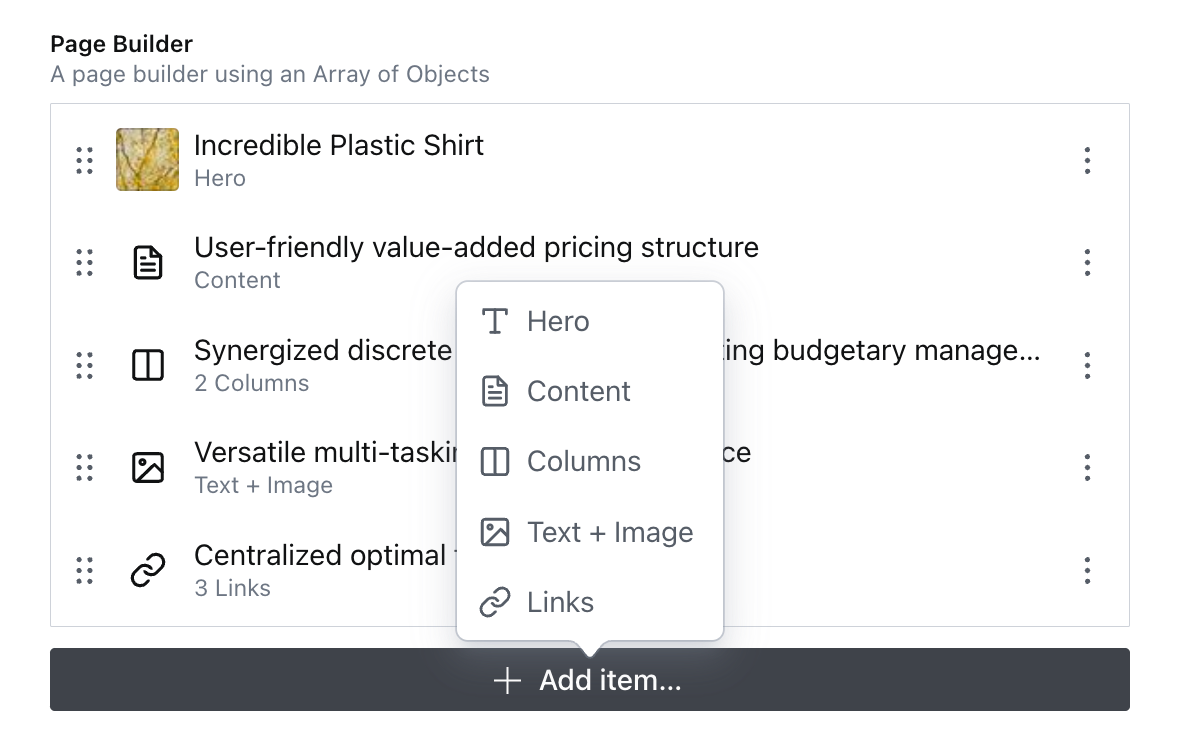
Creating a schema with many “Block” types each with unique fields seems like a good idea at first. Querying it seems straightforward too. You write a custom resolver for each block type, whether it exists in the document you’re querying or not.
Some blocks also need to resolve references, and those might also have nested references. Your query is getting long so you write some JavaScript functions to generate the full query string dynamically. Each page might only have a few block types but your query has to account for every unique object type that exists.
Soon enough, you’re sending query strings larger than the size of the data you’re receiving.
The Query API has a 300kb limit, and there’s a chance you’ll hit it.
If you’re querying for a page on a Next.js, Remix or similar website front-ends it probably looks like the below. Searching for a document based on its slug.current value, and uniquely resolving every potential _type in the Page Builder.
// Option 1: The Massive Payload Query
const page = await client.fetch(
`*[_type == "page" && slug.current == $slug][0]{
title,
pageBuilder[]{
_type == "pageBuilderHero" => {
title,
description,
"image": image.asset->{
_id,
metadata {
blurHash
}
}
},
_type == "pageBuilderLinks" => {
lead,
pages[]->{
_type,
title,
slug
}
},
// ...and so on for every unique _type in existence!
},
}`,
{slug}
)Resolving every possible _type when each page might only contain a few means our query is many times larger than it needs to be.
Also, since the $slug variable changes on each page, we’re still creating a uniquely cached CDN request each time as well.
Splitting this into two queries can create smaller – and ideally faster – queries.
If your Page Builder is an Array of Objects
With the below approach, fetching data requires two queries, but they'll be smaller, faster and still unique.
In the first query, all we want to return is:
- the
_idof the Page document to create the fastest possible second query - an array of the unique
_typenames in our page builder, to build the second query.
// Option 2: The Scoped, Type-Specific Query
const {_id, pageBuilderTypes} = await client.fetch(
`*[_type == "page" && slug.current == $slug][0]{
_id,
"pageBuilderTypes": array::unique(pageBuilder[]._type)
}`,
{slug}
)
// Returns:
// _id: 'asdf-1234'
// pageBuilderTypes: ['pageBuilderHero', 'pageBuilderLinks', ...etc]Now we’ll need a little JavaScript to generate our GROQ. You might want to create a separate file that contains all the different _type resolvers that were previously written into every query.
If we use the same _type names as the schema – we can map over the _types returned from the first query, to create a string that only includes what we need in the second.
const PAGE_BUILDER_TYPE_QUERIES = {
pageBuilderHero: `{
title,
description,
"image": image.asset->{
_id,
metadata {
blurHash
}
}
}`,
pageBuilderLinks: `{
lead,
pages[]->{
_type,
title,
slug
}
}`,
}
// Now we can scope our query down to just this _id and the page builder's types
const pageByScopedQuery = await client.fetch(
`*[_id == $_id][0]{
title,
// Add a filter to the array for safety, incase a type is added since the first query
"pageBuilder": pageBuilder[_type in $pageBuilderTypes]{
// And create a query string with just the types used in this document
${pageBuilderTypes
.map((type: string) => `_type == "${type}" => ${PAGE_BUILDER_TYPE_QUERIES[type]}`)
.join(',')}
}
}`,
// This variable came from our first query
{_id}
)If your Page Builder is an Array of References
Using an Array of References in your Page Builder allows for reuse of content across pages, at establishes a single point of truth for each “block” so that updating multiple pages is much simpler.
The typical “Massive Payload” way of resolving each block is similar. And we can use the same approach as above to split this into two steps.
Our first query will need to resolve each reference to get the _type of each reference, so that we can build out the correct query.
const {_id, pageBuilderRefs} = await client.fetch(
`*[_type == "page" && slug.current == $slug][0]{
_id,
"pageBuilderRefs": pageBuilder[]->{
_id,
_type
}
}`,
{slug}
)And instead of doing a single second query, we could use Promise.all to query each reference individually. Creating many, smaller queries.
const pageByPromiseAll = await Promise.all(
pageBuilderRefs.map(({_id, _type}: {_id: string; _type: string}) =>
client.fetch(`*[_id == $_id][0]${PAGE_BUILDER_TYPE_QUERIES[_type]}`, {_id})
)
)This even works for Portable Text!
Did you know the Portable Text field is also an array with unique _types? It’s easily overlooked!
Use the same code example ideas above to resolve only the types that the individual document you're querying uses.
Conclusion
The appeal of Page Building with Sanity is easy to see – however at a certain complexity you may need to adjust the way you query for this data. For smaller, more reliable queries.
Sanity – The Content Operating System that ends your CMS nightmares
Sanity replaces rigid content systems with a developer-first operating system. Define schemas in TypeScript, customize the editor with React, and deliver content anywhere with GROQ. Your team ships in minutes while you focus on building features, not maintaining infrastructure.
Sanity scales from weekend projects to enterprise needs and is used by companies like Puma, AT&T, Burger King, Tata, and Figma.



