An opinionated guide to Sanity Studio
Sanity Studio is an incredibly flexible tool with near limitless customisation. Here's how I use it.
This developer guide was contributed by Simeon Griggs (Principal Educator).
I’ve been creating Sanity projects since 2019 and, in that time, have developed a few preferences about how new Studios should be structured. I’ve had a version of this guide written down for quite some time as my own reference while testing new schema and plugins. As I spin up several new projects a month, this guide has become increasingly valuable.
Using Cursor?
I've compiled the majority of these opinions into a Cursor rules document you can add to any Sanity project so that as you prompt new configuration files into existence they follow these rules.
You can get my opinionated Sanity Studio Cursor rules here.
Read the documentation guide on AI-assisted Sanity development.
Why I wrote this guide
I hope that you find this guide useful to eliminate decision paralysis. When I first learned React, Sara Vieira’s Opinionated Guide to React was foundational in removing the sinking feeling of wondering if I was doing it wrong and instead showed one set of conventions I could accept. Paving the way to focusing on the job of actually solving problems.
The intention of this guide is not to slap your hand and make you feel bad if you’re not building Sanity projects just like me. If you feel stuck between multiple choices and need a little nudge to pick one and move forward, you can once you’ve read this guide!
The inverse is also true. These strong opinions are loosely held. The realities of your project may come into conflict with some of the patterns demonstrated here. Make adjustments as you feel if strict adherence to this guide slows down the progress toward your goals.
All of the following are my own personal opinions and do not represent those of Sanity or my colleagues in our wonderful engineering teams. There are valid reasons to diverge from the patterns demonstrated in this guide, and you should not feel bad if you do!
Getting started
Initialize any new Sanity Studio with the following command:
npm create sanity@latest -- --typescript --template clean
pnpm create sanity@latest --typescript --template clean
yarn create sanity@latest --typescript --template clean
bun create sanity@latest --typescript --template clean
Or to quickly generate a new project, use these additional flags:
npm create sanity@latest -- --template clean --create-project "showcase" --dataset production --typescript
pnpm create sanity@latest --template clean --create-project "showcase" --dataset production --typescript
yarn create sanity@latest --template clean --create-project "showcase" --dataset production --typescript
bun create sanity@latest --template clean --create-project "showcase" --dataset production --typescript
Why: I’ll never start a new project without TypeScript again and prefer to work with no schema files instead of modifying existing ones.
Linting and formatting
Install prettier and configure with eslint along with simple-import-sort.
npm install --save-dev eslint-plugin-prettier prettier eslint-plugin-simple-import-sort eslint-plugin-import
pnpm add --save-dev eslint-plugin-prettier prettier eslint-plugin-simple-import-sort eslint-plugin-import
yarn add --dev eslint-plugin-prettier prettier eslint-plugin-simple-import-sort eslint-plugin-import
bun add --dev eslint-plugin-prettier prettier eslint-plugin-simple-import-sort eslint-plugin-import
Replace eslint.config.js with the following:
// eslint.config.js
import studio from '@sanity/eslint-config-studio'
import prettier from 'eslint-plugin-prettier'
import simpleImportSort from 'eslint-plugin-simple-import-sort'
import importPlugin from 'eslint-plugin-import'
import * as typescriptEslint from '@typescript-eslint/eslint-plugin'
import typescriptParser from '@typescript-eslint/parser'
export default [
...studio,
{
ignores: ['dist', 'node_modules', '.sanity'],
files: ['**/*.ts', '**/*.tsx'],
plugins: {
prettier,
'simple-import-sort': simpleImportSort,
import: importPlugin,
'@typescript-eslint': typescriptEslint,
},
languageOptions: {
parser: typescriptParser,
parserOptions: {
project: './tsconfig.json',
ecmaVersion: 'latest',
sourceType: 'module',
},
},
rules: {
'prettier/prettier': 'error',
'simple-import-sort/imports': 'error',
'simple-import-sort/exports': 'error',
'@typescript-eslint/consistent-type-imports': 'error',
'import/no-default-export': 'error',
},
},
{
files: ['**/sanity.config.ts', '**/sanity.cli.ts'],
rules: {
'import/no-default-export': 'off',
},
},
]Add a linting command to your package.json file and run it to format all existing files instantly:
"scripts": {
// ...all other scripts
"lint": "eslint . --fix",
}Why: I never want unformatted code in any file in my codebase ever. I also want code formatting every time I press “save” on a file. Regarding options like line length, semicolons, or single vs double quotes, I agree with Prettier’s philosophy on options, and I genuinely don’t care.
That code is consistently formatted in every file of a project is far more important to me than how it is formatted.
General rules
The linting rules above include throwing an error if a default export is used. Default exports can create issues that are more difficult to debug, especially when renaming files or functions. Named exports are more explicit and, therefore, more reliable.
File organization
Create a /src directory and put /schemaTypes in it.
Note: A workspace can only have one “schema” which is a collection of “schema types.” So, it would be incorrect to use “schemas” here.
mkdir src; mv schemaTypes src/schemaTypes
Remember to also update the import to your schema types file in sanity.config.ts
// sanity.config.ts
import {schemaTypes} from './src/schemaTypes'All Sanity Studio-specific files will now live in ./src
For example, I like to create structure configuration files like so:
src/ └─ structure/ ├─ index.ts └─ defaultDocumentNode.ts
Why: I don’t like anything in the root directory other than project-impacting configuration files. Collating all Studio-specific files into a single folder makes it more easily portable between Studio projects.
Schema types and form components
All schema types should always use the defineType, defineField, and defineArrayMember helper plugins. They are optional, but they make authoring and debugging schema in TypeScript simpler.
All registered schema export a named const that matches the filename. This only applies if it does not have input components.
// src/schemaTypes/lessonType.ts
import {defineField, defineType} from 'sanity'
export const lessonType = defineType({
name: 'lesson',
title: 'Lesson',
type: 'document',
fields: [
defineField({
name: 'title',
type: 'string',
}),
],
})src/ └─ schemaTypes/ ├─ index.ts └─ lessonType.ts
If a schema type has input components, they should be colocated with the schema type file. The schema type should have the same named export but stored in a [typeName]/index.ts file:
// src/schemaTypes/seoType/index.ts
import {defineField, defineType} from 'sanity'
import seoInput from './seoInput'
export const seoType = defineType({
name: 'seo',
title: 'SEO',
type: 'object',
components: { input: seoInput }
// ...
})These components should be named [name]-[componentType]
src/
└─ schemaTypes/
└─ seoType/
├─ index.ts
├─ seoInput.ts
└─ seoField.tsThey can all be imported and collated in your schema types like this:
// src/schemaTypes/index.ts
import {lessonType} from './lessonType'
import {seoType} from './seoType'
export const schemaTypes = [lessonType, seoType]Why: Named exports are simpler to debug, import, and refactor.
Decorating schema types
Sanity Studio offers many ways to enrich the content editing UI on behalf of your authors – and you should use them.
Every document and object schema type should:
- Have an
iconproperty from either @sanity/icons, or if you need more variety, the Lucide set has a larger selection. - Have a customized
previewproperty so that desk lists, reference fields, and search results show rich content about the document. - Use Field Groups when the schema type has more than a few fields to collate related fields and only show the most important group by default. These Groups should use the
iconproperty as well.
Avoid boolean fields
Prefer string literal fields. The string field type accepts a list of options that the author can choose from.
It is tempting to use the boolean field type for instances where a document needs to express one of two "modes." In practice, two is often not enough and refactoring a boolean into a string field later is more work than adding more string options.
Consider the following scenario: You want some documents to be only available to "internal" users. You might create a boolean field named isInternal. You can enforce a default value in your GROQ queries like so:
"isInternal": isInternal == true
Later, a request is made for an indeterminate state, users who are logged in but not "internal." Do you create another boolean field? This complicates the logic further.
Instead, a more flexible way to achieve the same goal, create a string field named visibility with the options "public" and "internal." It can be extended to include "authenticated." Thanks to the coalesce function, a default value can still be returned from GROQ queries.
"visibility": coalesce(visibility, "public")
Avoid single references
Prefer an array of references. At the beginning of your project, with limited content, it may seem correct to use only a singular reference field. A post may only have one author. Eventually, your needs grow, and posts need multiple authors.
It is better to use plurals for your reference field names and prepare for a future where you have more than one – than have to refactor your fields, values, and GROQ queries later.
// ❌ Avoid single reference fields
defineField({
name: "author",
type: "reference",
to: { type: "author" },
})
// ✅ Prefer starting with an array of references
defineField({
name: "authors",
type: "array",
of: [defineArrayMember({ type: "reference", to: { type: "author" } })],
// Optionally limit the number of items
validation: (rule) => rule.max(1),
})Validation rules can enforce the maximum number of items in an array, so you could still limit the number of references to one.
And your GROQ queries can still return just a single reference.
"author": authors[0]->
Organizing plugin configuration files
Some plugins – like Structure and Presentation – may require complex configuration. Those files will need to live somewhere in your project.
Keep a ./src/plugins folder for any plugins you create in your Studio. There is an example of this in the next section.
Instead, create a folder for each plugin and store your configuration functions within these. For example, create a structure folder for your configuration of the structureTool plugin.
// sanity.config.ts
// ...other imports
import {structure, defaultDocumentNode} from './src/structure'
export default defineConfig({
// ...other settings
plugins: [
// ...other plugins
structureTool({structure, defaultDocumentNode})
],
})This should leave you with folder structures for the Structure and Presentation plugins like:
src
├─ structure
│ └─ index.ts
└─ presentation
└─ locate.tsCollate shared functionality as a custom plugin
If you are developing a suite of functions, components, and Studio features that are related – combine them as a new plugin. Plugins do not need to be distributed to npm – just create a plugins directory and store related files there.
Plugins in Sanity Studio v3 are mini encapsulations of a Workspace config. So you could register a new tool, schema, document badges and actions, form components, and more in a single file.
Why: This makes sharing functionality between projects simpler but can also help with debugging by being able to disable an entire set of features by removing a single plugin from the Workspace config.
Example plugin
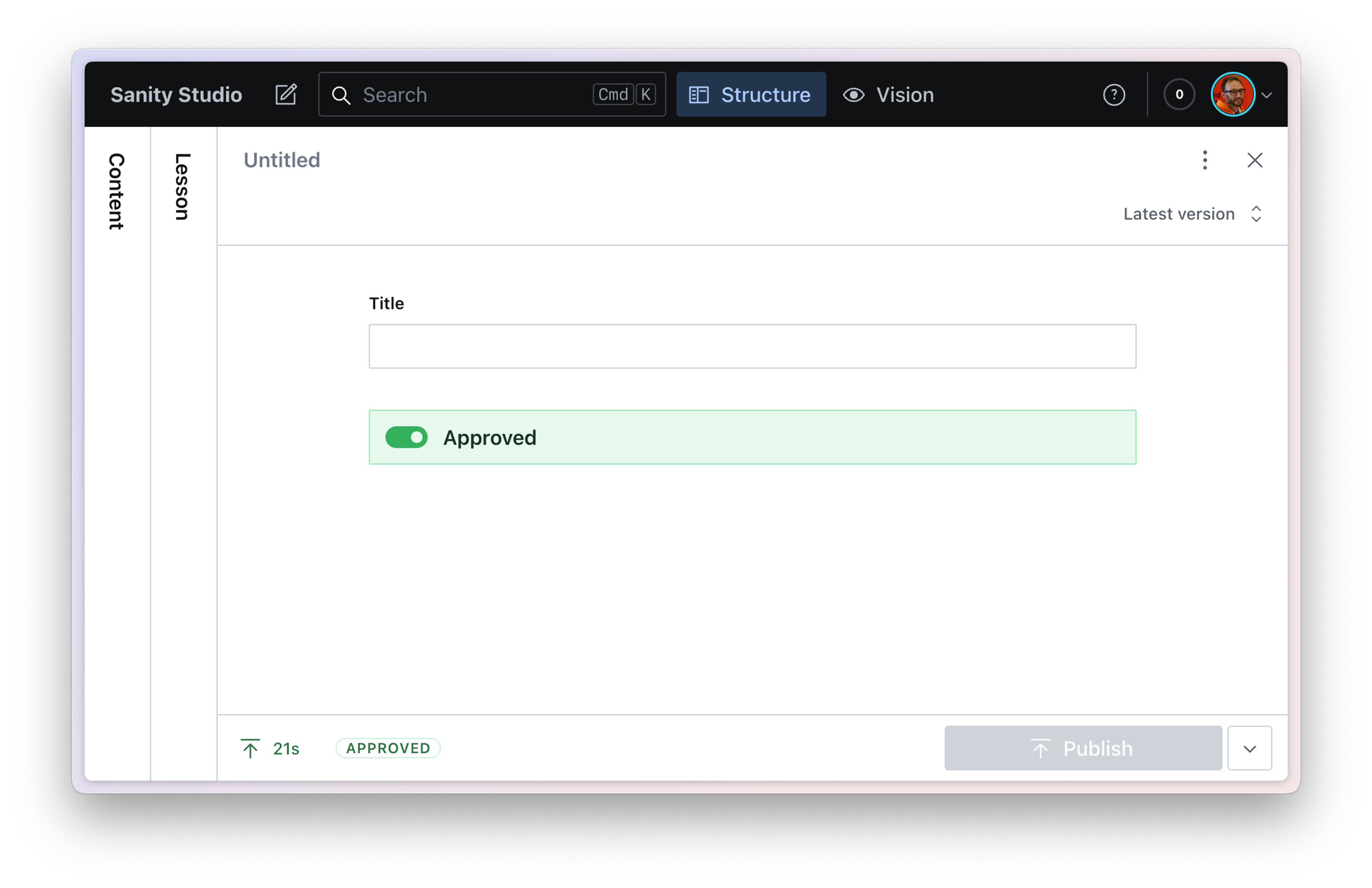
Imagine you’ve been tasked to indicate the exhilaration of an approval process in the Studio. To visualize this, you’ll build a custom form component to display confetti when a document is approved. As well as rendering a document badge on approved documents.
This requires several parts of the Studio configuration API and could be useful in more than a single project.
So you’d create a plugins folder inside your Studio, and in it, register the plugin’s schema types, form components, and document badges inside.
// src/plugins/approval/index.ts
import {definePlugin} from 'sanity'
import {ApprovedBadge} from './badges'
import {approvedType} from './schemaTypes/approvedType'
export const approval = definePlugin({
name: 'approval',
schema: {types: [approvedType]},
document: {badges: (prev) => [...prev, ApprovedBadge]},
})All these files would look like this in your project:
src
└─ plugins
└─ approval
├─ index.ts
├─ badges
│ └─ index.ts
└─ schemaTypes
├─ approvedType
│ ├─ ApprovedInput.tsx
│ └─ index.ts
└─ index.tsThe plugin can then be activated in the Studio by adding it to your sanity.config.ts and deactivated for specific users, environments, or just by commenting it out.
// sanity.config.ts
// ...other imports
import {approval} from './src/plugins/approval'
export default defineConfig({
// ...other settings
plugins: [
// ...other plugins
approval()
],
})Final folder structure for Studio projects
Putting all of the file tree diagrams together in the previous examples ends up with a Studio repository that looks something like this.
Note that this doesn't cover every permutation of the possibilities of handling multiple workspaces. You may choose to apply this differently.
src │ // Required: Root-level config files ├─ tsconfig.json ├─ package-lock.json ├─ package.json ├─ sanity.cli.ts ├─ sanity.config.ts │ // Optional: Root-level files ├─ .gitignore ├─ eslint.config.js ├─ README.md │ // Required: Automatically generated folders ├─ node_modules │ └─ ... ├─ dist │ └─ ... ├─ static │ └─ ... │ // Required: Configure your Studio schema types ├─ schemaTypes │ ├─ index.ts │ ├─ lessonType.ts │ └─ seoType │ ├─ index.ts │ ├─ seoField.ts │ └─ seoInput.ts │ // Optional: Configure Studio plugins and tools │ // Your Studio may have none, some or more than these ├─ actions │ └─ index.ts ├─ badges │ └─ index.ts ├─ plugins │ └─ approval │ ├─ badges │ │ └─ index.ts │ ├─ index.ts │ └─ schemaTypes │ ├─ approvedType │ │ ├─ ApprovedInput.tsx │ │ └─ index.ts │ └─ index.ts ├─ presentation │ └─ locate.ts └─ structure └─ index.ts │ // Optional: CLI commands ├─ migrations │ └─ ...
Embedded or standalone Studio
Since Sanity Studio is "just" a React component, it can be "embedded" in a route as part of your front-end application. This can be especially convenient if your use of Sanity is predominately relevant for your website.
However, this convenience potentially constrains your thinking for Sanity to website-specific use cases, and turns Sanity Studio into little more than a website CMS. This is a limited view of the potential of the Studio and structured content.
For teams with ambitious projects that go beyond modeling a website, it is preferable to maintain the Studio as a separate application – either with its own history of version control or in a mono-repo. So that its content could be consumed by many applications and its configuration committed to by many developer teams.
Writing and formatting GROQ queries
Variable names used for GROQ queries should be written in “screaming snake case,” for example, POSTS_QUERY. This is purely a stylistic preference and has no functional benefit. Remember: this is an extremely opinionated guide.
In many programming languages, this casing is used for variables that are not expected to change. While your GROQ query can be any string value, it should be considered an anti-pattern to generate them from functions or have logic in your app modify the query string.
GROQ query strings should be prefixed with the defineQuery helper from the groq package, as it provides syntax highlighting in VS Code when you have the Sanity.io VS Code extension installed, and are required when using Sanity TypeGen.
import { defineQuery } from 'groq'
export const POSTS_QUERY = defineQuery(`*[_type == "post"]`)Short queries like the above are fine on one line. Longer queries, especially those with projections, should use many lines so the logic in both the filter (the [] bit) and projection (the {} bit) are easier to read. They’re also simpler to debug, as you can remove filter arguments or parts of the projection by commenting out those lines.
export const POST_QUERY = defineQuery(`*[
_type == "post"
&& slug.current == $slug
][0]{
_id,
title,
image,
author->{
_id,
name
}
}`)Explicit projections
Array/Object expansion (three dots like this ... commonly called a “spread” operator) should be used sparingly.
During development, you may find it simpler not to use a projection or return all attributes in a filter using this operator. However, this leads to “over-fetching,” where more data is returned than necessary. Slowing down response times.
Explicitly naming attributes in a projection also makes it clearer what data is relied upon by the application that consumes it.
By the time your app is in production:
- Every filter
[]in every GROQ query should have a projection - No query projection
{}should contain array/object expansion... - Query projections should explicitly name the attributes required
One way to ensure parity between your queries and your application is to run the result of your query through a validation library like Zod. This can validate returned data to ensure attributes are the correct value, and strict mode checking ensures no missing or additional attributes. It will also help by generating TypeScript types.
You’ll likely be less frustrated adding Zod the sooner you add it to a project, so I recommend it during development. For more on this topic, I have written a separate blog post on using Zod with Sanity.
// Not good, what data is your app actually using?
*[_type == "post"]
// Still not good, now also returning way too much data
*[_type == "post"]{
...,
categories[]->
}
// Better!
*[_type == "post"]{
title,
slug,
categories[]->{ title, slug }
}Filter out nulls and set fallback values
By default, when you name individual attributes to retrieve in a GROQ query, any empty value will return null. Because of this your application will need to do a lot of defensive coding ("null checking") to see if a value exists.
Take this query for example:
// Without naming attributes, any of them could be undefined
*[_type == "post"]
// Naming these attributes will return their keys
// but slug.current could be null and trying to
// access it could throw an error
*[_type == "post"]{
title,
slug,
categories[]->{ title, slug }
}Now consider how our application needs to handle this data.
In the (not great) React component example code below you must check that categories is an array, not null. And check slug.current exists, and is not null.
{Array.isArray(post.categories) ? (
<ul>
{post.categories.map((category, index) => (
<li key={category?.slug?.current || index}>
{category?.slug?.current ? (
<a href={`/categories/${category.slug.current}`}>
{category.title}
</a>
) : (
category.title
)}
</li>
))}
</ul>
) : null}When configuring Visual Editing your application may be consuming data from queries for draft document that only have null values.
Guard against documents that will return null values by filtering them out of results. The GROQ function defined() will check if a value is null.
// Filter out any documents that don't have slug.current
*[
_type == "post"
&& !defined(slug.current)
]{
title,
slug,
categories[]->{ title, slug }
}Prevent attributes from returning null by using the GROQ function coalesce() to return a different value, if the current value would return null.
In this example categories always returns an array.
// categories could be an array or null, annoying to check for
*[
_type == "post"
&& defined(slug.current)
]{
title,
slug,
categories[]->{ title, slug }
}
// return categories if they exist, or an empty array
*[
_type == "post"
&& defined(slug.current)
]{
title,
slug,
"categories": coalesce(
categories[]->{ title, slug },
[]
)
}Variables vs string interpolation
Use $variables in your queries instead of string interpolation to insert values.
Variables are safer and make queries easier to understand.
// Don't do this, it breaks easily and is difficult to read
const TYPE_QUERY = (type) => defineQuery(`*[_type == "${type}"]`)
// Do this and pass parameters to Sanity Client
const TYPE_QUERY = defineQuery(`*[_type == $type]`)There are occasions when string interpolation is unavoidable. It’s currently not possible to use variables to declare attributes. So the following is acceptable.
const fieldName = 'bedrooms'
const FIELD_QUERY = defineQuery(`*[${fieldName} > 5]`)"Fragments"
Rules were meant to be broken!
An exception to several of the opinions above is when you wish to re-use a GROQ query’s filter or projection inside of multiple queries, as GROQ does not yet support “fragments” or reusable query segments.
In the example below, a GROQ projection has been created as its own standalone variable, which can be reused with string interpolation into multiple complete query strings.
const PAGE_BUILDER_PROJECTION = defineQuery(`{
_key,
_type,
// ...any other attributes common to all types
_type == "pageBuilderVideo" => {
video->
},
_type == "pageBuilderTeam" => {
staff[]->
},
}`)
export const PAGE_QUERY = defineQuery(`*[_type == "page" && slug.current == $slug][0]{
_id,
title,
pageBuilder[]${PAGE_BUILDER_PROJECTION},
}`)
export const HOME_QUERY = defineQuery(`*[_id == "home"][0]{
_id,
title,
pageBuilder[]${PAGE_BUILDER_PROJECTION},
}`)To demonstrate just how loosely held these strong opinions are – here’s a guide I wrote for this precise kind of query where a helper function is used to build a GROQ query dynamically.
Custom GROQ functions
String interpolation works well for sharing GROQ across queries in your application code, but the function definitions still live as plain strings. Custom GROQ functions offer a GROQ-native alternative: declare a function once at the top of a query, then call it like any built-in function.
import {defineQuery} from 'groq'
const postQuery = defineQuery(`
fn ex::author($author) = $author-> {
"name": firstName + " " + lastName,
"slug": slug.current,
};
*[_type == "post"] {
title,
"author": ex::author(author)
}
`)Custom functions must be declared at the start of each query because there is no global function registry on the server. To reuse a function across multiple queries, the string interpolation pattern still applies: define the function declaration as a constant and prepend it where needed. The two patterns are complementary, custom functions give you a GROQ-native syntax for the projection itself, and string interpolation lets you share that declaration across queries in your codebase.
Have I missed anything?
If there’s any part of working with Sanity Studio, Sanity Client, or any of the APIs where you’ve got it working but aren’t quite convinced you’re doing it right, please let me know!
Extra reading
Some more opinionated reading that unpack opinionated guides or best practices for other parts of the Sanity ecosystem: