Published August 28, 2019
Importing data from external sources
By Bjørge Næss

As a Sanity developer you often find yourself in need of importing data from an external source. For example when you are doing a one-time import from another CMS over to Sanity, or when you just want to clean up messy data from an external API or restful web service, or if you want the ability to do powerful queries on it.
In this guide we will cover how to do a one-time import from an external data source using Node.JS.
Concepts you should have basic familiarity with:
- Node.js and Promise API
What are some common external sources? An external data source can be a wide range of different formats made available on a wide range of different transport layers. Here are a few examples:
- The rest API of your old CMS
- A text file with comma separated values (CSV)
- A SQL database
- A JSON file or newline delimited JSON (NDJSON) file
The anatomy of an external data import
No matter what kind of source you are reading from, an external import can be split into three discrete steps:
- Read data from external source
- Transform to sanity document(s) matching your data model
- Save the documents to your sanity dataset
We will cover each of these in order
Step 1: Read data from an external source
Let's start with a simple example where the external data source is an API endpoint file containing an array of two breeds of cats that we want to import into a sanity dataset.
[
{
"id": 1,
"breed": "Abyssinian",
"country": "Ethiopia",
"origin": "Natural",
"body type": "Oriental",
"coat": "Short",
"pattern": "Ticked"
},
{
"id": 2,
"breed": "Aegean",
"country": "Greece",
"origin": "Natural",
"body type": "",
"coat": "Semi-long",
"pattern": "Bicolored or tricolored"
}
//...
]The quickest way to read from this API in Node.js is to install the node-fetch-package which gives you a window.fetch-like API that enables you to fetch the data with
const CAT_API_URL = 'https://cat-api-bjoerge.sanity-io1.now.sh/cats'
fetch(CAT_API_URL)
.then(res => res.json())
.then(catBreeds => {
// we now have an array of catBreeds from the external API
})Step 2: Transform to sanity document(s) matching your data model
Now, let's say the following is the Sanity schema we want our imported data to adhere to:
./schema.js
{
type: 'document',
name: 'catBreed',
fields: [
{name: 'name', type: 'string'},
{name: 'country', type: 'reference', to: [{type: 'country'}]},
{name: 'bodyType', type: 'string'},
{name: 'coat', type: 'string'},
{name: 'pattern', type: 'string'}
]
},
{
type: 'document',
name: 'country',
fields: [
{name: 'name', type: 'string'}
]
}If you look carefully, you'll see that the source data doesn't map 1:1 to the schema model. According to our sanity schema, a cat breed will be stored like this:
{
name: 'Abyssinian',
country: {_type: 'reference', _ref: 'ethiopia'},
bodyType: 'Oriental',
coat: 'Short',
pattern: 'Ticked'
}There are a few differences to note here:
- The
breedfield callednamein our sanity data model - Instead of importing country directly, we want a separate record of the country, and have the country field be a reference to it instead.
- Instead of
body type, it must bebodyType(note the camelCase). - The
originfield from the external API isn't relevant to us, and we don't want to import it at all. - To further complicate things, this API does not provide any ID to uniquely identify each record.
This can roughly be codified to the following transform function:
function transform(externalCat) {
return {
_id: ??,
_type: 'catBreed',
name: externalCat.breed,
country: ??,
bodyType: externalCat['body type'],
coat: externalCat.coat,
pattern: externalCat.pattern
}
}ProTip: Make predictable IDs
So when importing data from an external data source, you usually want to be able to run the import several times without adding new records every time (we developers hardly ever get it right the first time, right?). It is usually a good idea to think about ways of uniquely identifying each record from an external source. Since _ids in Sanity can be any string, a neat trick is to assign IDs to your documents before submitting them to the sanity datastore. If you do this together with the createOrReplace mutation you will ensure that you never get duplicate records when running the import multiple times. Note: you still need to make sure the ID doesn't collide with other documents and that it adheres to the format of Sanity document IDs.
Luckily, the array entries returned from the cat API all seem to all have a unique id. So let's use that as a part of the sanity document id. In order to avoid collisions with other documents, it's a good idea to prefix the id with something, in this case, we'll prefix the external id with imported-cat-. (As a bonus, this also makes it easy to identify documents coming from external sources).
Going back to our transform function, we can specify the ID like this:
function transformCat(externalCat) {
return {
_id: `imported-cat-${externalCat.id}`, // use the id of the record from the external source (we happen to know the API only return unique values for `id`)
_type: 'catBreed',
name: externalCat.breed,
country: ??,
bodyType: externalCat['body type'],
coat: externalCat.coat,
pattern: externalCat.pattern
}
}Now the remaining question is how do we create a reference to the country record? There are two things to keep in mind here:
- When creating a reference, the document you are referring to needs to exist already. Sanity will not allow you to create references to documents that do not exist*
- For each country, you may encounter we only want a single record
But let's worry about a single thing at a time. It's always a good thing to keep the transformation separate from the actual posting, so to begin with let's just return all the documents we need, and then worry about the order of things after.
So, instead of making our transformCat function return a single document, let's make it return both the transformed cat and the country:
function transform(externalCat) {
const countryId = externalCat.country.toLowerCase()
const country = {
_type: 'country',
_id: countryId,
name: externalCat.country
}
const cat = {
_id: externalCat.breed.toLowerCase(), // use the breed name as unique id (we happen to know the API only return unique values for `breed`)
_type: 'catBreed',
name: externalCat.breed,
country: {_type: 'reference', _ref: countryId}, // we have now created the reference to the country id
bodyType: externalCat['body type'],
coat: externalCat.coat,
pattern: externalCat.pattern
}
return [country, cat]
}Now our transform function returns two documents for every cat instead of one, and there's likely to be a lot of duplicate country documents in there, but let's save the optimization for later.
What we have so far:
const CAT_API_URL = 'https://guide-cat-api.sanity-io.now.sh/cats'
fetch(CAT_API_URL)
.then(res => res.json())
.then(catBreeds => catBreeds.map(transform))
.then(documents =>
// documents is now an array of [country, cat], so we need to flatten it. We'll use lodash.flatten for that
flatten(documents)
)
.then(documents =>
// now we have all our documents and are ready to save them to our dataset
)Now we have all the documents we want to import into the Sanity Datastore.
Step 3: Importing to Sanity.io
In the previous steps, all we did was fetch and prepare the data to be imported into your Sanity dataset. Now it's time to actually make it become Sanity documents.
Note: the next step is also covered in the Importing Data documentation
First, we need to configure our Sanity client with our project ID and the dataset we want to store the JSON documents in.
We will need to add @sanity/client as a dependency to our project, and import the client factory and create a client instance for our project ID and dataset:
const sanityClient = require('@sanity/client')
const client = sanityClient({
projectId: '<your-project-id>',
dataset: '<your-dataset>',
token: '<your-token-with-write-access>', // we need this to get write access
useCdn: false // We can't use the CDN for writing
})In order to give this client write access, we need to generate an access token. You can generate an access token under the API section of your project's settings on manage.sanity.io.
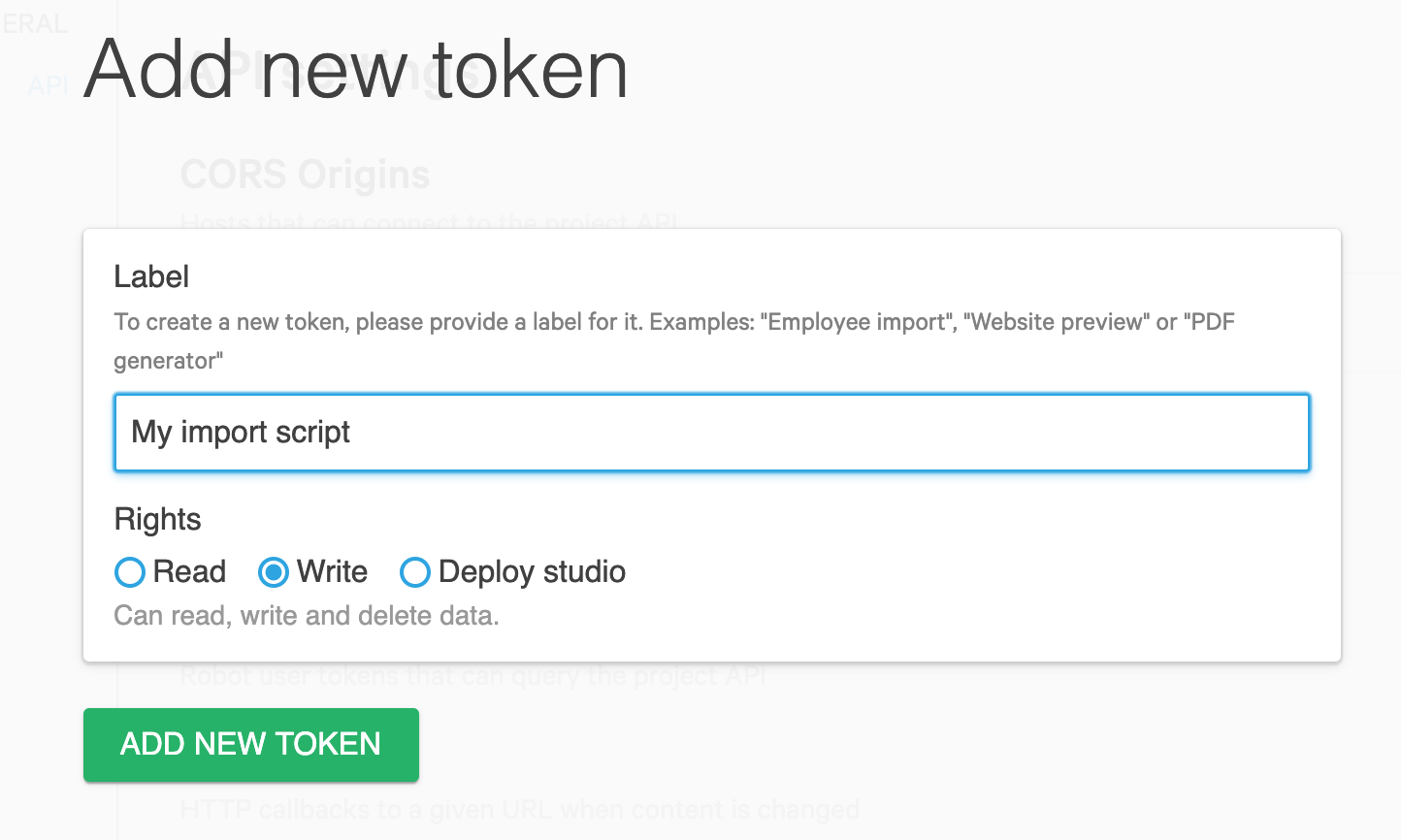
Now that we have our Sanity client configured, the next step is to create our documents in the Sanity dataset. All write operations are done by submitting mutations to the /data/mutate/<dataset> API endpoint. The Sanity.io API supports a range of mutations types that allows you to formulate a fine-grained description of the write operation you want to do: create, createIfNotExists, createOrReplace, delete and patch.
The Sanity client we just configured makes submitting mutations a matter of calling a method. Here's an example:
client.create({
_id: 'my-test-cat',
type: 'catBreed'
name: 'Test Cat'
})All the mutation types have a corresponding method on the client instance. See the JavaScript client documentation and the mutations API documentation for more details.
Going back to our example, we now want to take the documents that we have transformed to Sanity documents, and write them to our dataset.
Since we're likely to want to tweak and fine-tune our import script, we should cater to running it several times. This is a perfect fit for the createOrReplace mutation, as it will create the document if it doesn't already exist, or replace it if it does exist (The create-mutation will fail if you try to create a document with an id that's already taken).
Let's pull it all together and use the client naively to post mutations to the dataset. Since the Sanity datastore requires documents that are referred to by other documents to exist already, we need to make sure we post the countries first, and then the cats that have a reference to the country documents after.
const sanityClient = require('@sanity/client')
const CAT_API_URL = 'https://guide-cat-api.sanity-io.now.sh/cats'
const client = sanityClient({
projectId: 'xHrcat8Du4',
dataset: 'cats',
// a token with write access
token: 'catCARKCoLccJKPCaTzAxmecaTj0IdCMcatYJPMxzNYmmO3d0gROoS',
useCdn: false
})
fetch(CAT_API_URL)
.then(res => res.json())
.then(catBreeds => catBreeds.map(transform))
.then(pairs =>
// documents is now an array of [country, cat], so we need to flatten it.
// We'll use lodash.flatten for that
flatten(documents)
)
.then(documents => {
const countries = documents.filter(doc =>
doc._type === 'country'
)
const catBreeds = documents.filter(doc =>
doc._type === 'catBreed'
)
// Write all countries to the dataset using a createOrReplace mutation
const allCountriesWritten = Promise.all(countries.map(country =>
client.createOrReplace(country)
))
// After the countries has been written, go ahead and create (or replace) the cat documents
const allCatsWritten = allCountriesWritten.then(() =>
Promise.all(catBreeds.map(cat => client.createOrReplace(cat)))
)
// continue when all cats has been written
return allCatsWritten
})Although this looks quite right on the surface, this code is likely to be rejected by the Sanity API when run. As it stands above, for each country and each cat we will be issuing a separate request to the API, also, every request will be performed in parallel. Since the mutation API has a rate limit of 25 req/s, this script is likely to hit this limit, causing the import script to error with a HTTP 429 response.
Depending on the size of the data you are importing, there are several ways of working around this. If like in our cats example, we're dealing with a rather small number of documents, they will safely be within the 100MB limit for a single mutation request, so instead of issuing a single request per document, we can chunk all of them into a single transaction, and submit them in a single API request. As a bonus, our code also becomes cleaner, and we don't need to worry about the order anymore, as you can create references to documents that get created in the same transaction:
fetch(CAT_API_URL)
.then(res => res.json())
.then(catBreeds => catBreeds.map(transform))
.then(pairs =>
// pairs is now an array of [country, cat], so we need to flatten it.
// We'll use lodash.flatten for that
flatten(pairs)
)
.then(documents => {
let transaction = client.transaction()
documents.forEach(document => {
transaction.createOrReplace(document)
})
return transaction.commit()
})After running this script we should now have all the cats from the external API in our Sanity dataset, and we should be able to do some queries, for example:
Get the name of all cat breeds from the United States:
*[_type=='catBreed' && country._ref == 'united-states'].name [ "Balinese", "Bambino", "Bengal", "Bombay", "California Spangled", "Chantilly-Tiffany", "Cheetoh", "American Curl", //... ]
Get three cat breeds and the name of their country of origin:
*[_type=='catBreed'][0...3].{
name,
"country": country->name
}
[
{
"country": "Ethiopia",
"name": "Abyssinian"
},
{
"country": "United Kingdom",
"name": "Asian"
},
{
"country": "United Kingdom",
"name": "Asian Semi-longhair"
}
]Also, if you have set up a studio with the schema above, you should see the cats in there too 😻
Importing assets (images and files)
When importing content to Sanity you may also want to import binary data like images and files. Here's how you can upload an image from an external url using node-fetch and the Sanity client:
const fetch = require('node-fetch')
const imageUrl = 'https://upload.wikimedia.org/wikipedia/commons/1/15/White_Persian_Cat.jpg'
fetch(imageUrl)
.then(res => res.buffer())
.then(buffer => client.assets.upload('image', buffer))
.then(assetDocument => {
// ...
})The assetDocument here is a Sanity document of the built-in type sanity.imageAsset, that is added to your dataset. This document contains a lot of useful metadata about the uploaded file (e.g. size, mime-type, color palette, LQIP), and the CDN URL where it is available. For more details about what kind of metadata we keep about images, please refer to our docs on assets.
If you are importing local data the Sanity client also accepts uploading from a node readable stream:
const fs = require('fs')
const stream = fs.createReadableStream('./cat.gif')
client.assets.upload('image', stream)
.then(assetDocument => {
// ...
})Uploading binary files (e.g. PDFs) works the same way, just use file as asset type instead of image: client.assets.upload('file', stream)
Further reading:
When importing a large number of documents, there are a few things to be aware of in terms of restrictions enforced by the Sanity API. You can read more about common pitfalls when importing data using the API client here.
(*) The Sanity datastore also offers a concept of weak refs, which enables referencing to a document that does not exist. There are situations where it makes sense to use weak references, but in most cases, we recommend using regular (strong) references.
Sanity – The Content Operating System that ends your CMS nightmares
Sanity replaces rigid content systems with a developer-first operating system. Define schemas in TypeScript, customize the editor with React, and deliver content anywhere with GROQ. Your team ships in minutes while you focus on building features, not maintaining infrastructure.
Sanity scales from weekend projects to enterprise needs and is used by companies like Puma, AT&T, Burger King, Tata, and Figma.